Матрица переходных вероятностей маркова. Структура данных Dictogram. Список использованной литературы
Марковская цепь - такая цепь событий в которой вероятность каждого события зависит только от предыдущего состояния.
Настоящая статья носит реферативный характер, написана на основе приведенных в конце источников, которые местами цитируются.
Введение в теорию марковских цепей
Цепью Маркова называют такую последовательность случайных событий, в которой вероятность каждого события зависит только от состояния, в котором процесс находится в текущий момент и не зависит от более ранних состояний. Конечная дискретная цепь определяется:
∑ j=1…n p ij = 1
Пример матрицы переходных вероятностей с множеством состояний S = {S 1 , …, S 5 }, вектором начальных вероятностей p (0) = {1, 0, 0, 0, 0}:
С помошью вектора начальных вероятностей
и матрицы переходов можно вычислить
стохастический вектор p (n) - вектор,
составленный из вероятностей p (n) (i) того, что процесс окажется в состоянии
i в момент времени n. Получить p (n) можно с помощью формулы:
помошью вектора начальных вероятностей
и матрицы переходов можно вычислить
стохастический вектор p (n) - вектор,
составленный из вероятностей p (n) (i) того, что процесс окажется в состоянии
i в момент времени n. Получить p (n) можно с помощью формулы:
p (n) = p (0) ×P n
Векторы p (n) при росте n в некоторых случаях стабилизируются - сходятся к некоторому вероятностному вектору ρ, который можно назвать стационарным распределением цепи. Стационарность проявляется в том, что взяв p (0) = ρ, мы получим p (n) = ρ для любого n.
Простейший критерий, который гарантирует сходимость к стационарному распределению, выглядит следующим образом: если все элементы матрицы переходных вероятностей P положительны, то при n, стремящемуся к бесконечности, вектор p (n) стремится к вектору ρ, являющемуся единственным решением системы вида
Также можно показать, что если при каком-нибудь положительном значении n все элементы матрицы P n положительны, тогда вектор p (n) все-равно будет стабилизироваться.
Доказательство этих утверждений есть в в подробном виде.
Марковская цепь изображается в виде графа переходов, вершины которого соответствуют состояниям цепи, а дуги - переходам между ними. Вес дуги (i, j), связывающей вершины si и sj будет равен вероятности pi(j) перехода из первого состояния во второе. Граф, соответствующий матрице, изображенной выше:
К лассификация
состояний марковских цепей
лассификация
состояний марковских цепей
При рассмотрении цепей Маркова нас может интересовать поведение системы на коротком отрезке времени. В таком случае абсолютные вероятности вычисляются с помощью формул из предыдущего раздела. Однако более важно изучить поведение системы на большом интервале времени, когда число переходов стремится к бесконечности. Далее вводятся определения состояний марковских цепей, которые необходимы для изучения поведения системы в долгосрочной перспективе.
Марковские цепи классифицируются в зависимости от возможности перехода из одних состояний в другие.
Группы состояний марковской цепи (подмножества вершин графа переходов), которым соответствуют тупиковые вершины диаграммы порядка графа переходов, называются эргодическими классами цепи. Если рассмотреть граф, изображенный выше, то видно, что в нем 1 эргодический класс M1 = {S5}, достижимый из компоненты сильной связности, соответствующей подмножеству вершин M2 = {S1, S2, S3, S4}. Состояния, которые находятся в эргодических классах, называются существенными, а остальные - несущественными (хотя такие названия плохо согласуются со здравым смыслом). Поглощающее состояние si является частным случаем эргодического класса. Тогда попав в такое состояние, процесс прекратится. Для Si будет верно pii = 1, т.е. в графе переходов из него будет исходить только одно ребро - петля.
Поглощающие марковские цепи используются в качестве временных моделей программ и вычислительных процессов. При моделировании программы состояния цепи отождествляются с блоками программы, а матрица переходных вероятностей определяет порядок переходов между блоками, зависящий от структуры программы и распределения исходных данных, значения которых влияют на развитие вычислительного процесса. В результате представления программы поглощающей цепью удается вычислить число обращений к блокам программы и время выполнения программы, оцениваемое средними значениями, дисперсиями и при необходимости - распределениями. Используя в дальнейшем эту статистику, можно оптимизировать код программы - применять низкоуровневые методы для ускорения критических частей программы. Подобный метод называется профилированием кода.
Например, в алгоритме Дейкстры присутствуют следующие состояния цепи:
vertex (v), извлечение новой вершины из очереди с приоритетами, переход только в состояние b;
begin (b), начало цикла перебора исходящих дуг для процедуры ослабления;
analysis (a), анализ следующей дуги, возможен переход к a, d, или e;
decrease (d), уменьшение оценки для некоторой вершины графа, переход к a;
end (e), завершение работы цикла, переход к следующей вершине.
Остается задать вероятности переходом между вершинами, и можно изучать продолжительности переходов между вершинами, вероятности попадания в различные состояния и другие средние характеристики процесса.
Аналогично, вычислительный процесс, который сводится к обращениям за ресурсами системы в порядке, определяемом программой, можно представить поглощающей марковской цепью, состояния которой соответствуют использованию ресурсов системы – процессора, памяти и периферийных устройств, переходные вероятности отображают порядок обращения к различным ресурсам. Благодаря этому вычислительный процесс представляется в форме, удобной для анализа его характеристик.
Цепь Маркова называется неприводимой, если любое состояние Sj может быть достигнуто из любого другого состояния Si за конечное число переходов. В этом случае все состояния цепи называются сообщающимися, а граф переходов является компонентой сильной связности. Процесс, порождаемый эргодической цепью, начавшись в некотором состоянии, никогда не завершается, а последовательно переходит из одного состояния в другое, попадая в различные состояния с разной частотой, зависящей от переходных вероятностей. Поэтому основная характеристика эргодической цепи –
вероятности пребывания процесса в состояниях Sj, j = 1,…, n, доля времени, которую процесс проводит в каждом из состояний. Неприводимые цепи используются в качестве моделей надежности систем. Действительно, при отказе ресурса, который процесс использует очень часто, работоспособность всей системы окажется под угрозой. В таком случае дублирование такого критического ресурса может помочь избежать отказов. При этом состояния системы, различающиеся составом исправного и отказавшего оборудования, трактуются как состояния цепи, переходы между которыми связаны с отказами и восстановлением устройств и изменением связей между ними, проводимой для сохранения работоспособности системы. Оценки характеристик неприводимой цепи дают представление о надежности поведения системы в целом. Также такие цепи могут быть моделями взаимодействия устройств с задачами, поступающими на обработку.
Примеры использования
Система обслуживания с отказами
Сервер, состоит из нескольких блоков, например модемов или сетевых карт, к которым поступают запросы от пользователей на обслуживание. Если все блоки заняты, то запрос теряется. Если один из блоков принимает запрос, то он становится занятым до конца его обработки. В качестве состояний возьмем количество незанятых блоков. Время будет дискретно. Обозначим за α вероятность поступления запроса. Также мы считаем, что время обслуживания также является случайным и состоящим из независимых продолжений, т.е. запрос с вероятностью β обслуживается за один шаг, а с вероятностью (1 - β) обслуживается после этого шага как новый запрос. Это дает вероятность (1 - β) β для обслуживания за два шага, (1 - β)2 β для обслуживания за три шага и т.д. Рассмотрим пример с 4 устройствами, работающими параллельно. Составим матрицу переходных вероятностей для выбранных состояний:
М ожно
заметить, что она имеет единственный
эргодический класс, и, следовательно,
система p × P = p в классе вероятностных
векторов имеет единственное решение.
Выпишем уравнения системы, позволяющей
находить это решение:
ожно
заметить, что она имеет единственный
эргодический класс, и, следовательно,
система p × P = p в классе вероятностных
векторов имеет единственное решение.
Выпишем уравнения системы, позволяющей
находить это решение:


Теперь известен набор вероятностей πi того, что в стационарном режиме в системе будет занято i блоков. Тогда долю времени p 4 = С γ 4 /4 в системе заняты все блоки, система не отвечает на запросы. Полученные результаты распространяются на любое число блоков. Теперь можно воспользоваться ими: можно сопоставить затраты на дополнительные устройства и уменьшение времени полной занятости системы.
Подробнее можно ознакомиться с этим примером в .
Процессы принятия решений с конечным и бесконечным числом этапов
Рассмотрим процесс, в котором есть несколько матриц переходных вероятностей. Для каждого момента времени выбор той или иной матрицы зависит от принятого нами решения. Понять вышесказанное можно на следующем примере. Садовник в результате анализа почвы оценивает ее состояние одним из трех чисел: (1) - хорошее, (2) - удовлетворительное или (3) - плохое. При этом садовник заметил, что продуктивность почвы в текущем году зависит только от ее состояния в предыдущем году. Поэтому вероятности перехода почвы без внешних воздействий из одного состояния в другое можно представить следующей цепью Маркова с матрицей P1:
Л огично,
что продуктивность почвы со временем
ухудшается. Например, если в прошлом
году состояние почвы было удовлетворительное,
то в этом году оно может только остаться
таким же или стать плохим, а хорошим
никак не станет. Однако садовник может
повлиять на состояние почвы и изменить
переходные вероятности в матрице P1 на
соответствующие им из матрицы P2:
огично,
что продуктивность почвы со временем
ухудшается. Например, если в прошлом
году состояние почвы было удовлетворительное,
то в этом году оно может только остаться
таким же или стать плохим, а хорошим
никак не станет. Однако садовник может
повлиять на состояние почвы и изменить
переходные вероятности в матрице P1 на
соответствующие им из матрицы P2:
Т еперь
можно сопоставить каждому переходу из
одного состояния в другое некоторую
функцию дохода, которая определяется
как прибыль или убыток за одногодичный
период. Садовник может выбирать
использовать или не использовать
удобрения, именно от этого будет зависеть
его конечный доход или убыток. Введем
матрицы R1 и R2, определяющие функции
дохода в зависимости от затрат на
удобрения и качества почвы:
еперь
можно сопоставить каждому переходу из
одного состояния в другое некоторую
функцию дохода, которая определяется
как прибыль или убыток за одногодичный
период. Садовник может выбирать
использовать или не использовать
удобрения, именно от этого будет зависеть
его конечный доход или убыток. Введем
матрицы R1 и R2, определяющие функции
дохода в зависимости от затрат на
удобрения и качества почвы:
Н аконец
перед садовником стоит задача, какую
стратегию нужно выбрать для максимизации
среднего ожидаемого дохода. Может
рассматриваться два типа задач: с
конечным и бесконечным количеством
этапов. В данном случае когда-нибудь
деятельность садовника обязательно
закончится. Кроме того, визуализаторы
решают задачу принятия решений для
конечного числа этапов. Пусть садовник
намеревается прекратить свое занятие
через N лет. Наша задача теперь состоит
в том, чтобы определить оптимальную
стратегию поведения садовника, то есть
стратегию, при которой его доход будет
максимальным. Конечность числа этапов
в нашей задаче проявляется в том, что
садовнику не важно, что будет с его
сельскохозяйственным угодьем на N+1 год
(ему важны все года до N включительно).
Теперь видно, что в этом случае задача
поиска стратегии превращается в задачу
динамического программирования. Если
через fn(i) обозначить максимальный
средний ожидаемый доход, который можно
получить за этапы от n до N включительно,
начиная из состояния с номером i, то
несложно вывести рекуррентное
аконец
перед садовником стоит задача, какую
стратегию нужно выбрать для максимизации
среднего ожидаемого дохода. Может
рассматриваться два типа задач: с
конечным и бесконечным количеством
этапов. В данном случае когда-нибудь
деятельность садовника обязательно
закончится. Кроме того, визуализаторы
решают задачу принятия решений для
конечного числа этапов. Пусть садовник
намеревается прекратить свое занятие
через N лет. Наша задача теперь состоит
в том, чтобы определить оптимальную
стратегию поведения садовника, то есть
стратегию, при которой его доход будет
максимальным. Конечность числа этапов
в нашей задаче проявляется в том, что
садовнику не важно, что будет с его
сельскохозяйственным угодьем на N+1 год
(ему важны все года до N включительно).
Теперь видно, что в этом случае задача
поиска стратегии превращается в задачу
динамического программирования. Если
через fn(i) обозначить максимальный
средний ожидаемый доход, который можно
получить за этапы от n до N включительно,
начиная из состояния с номером i, то
несложно вывести рекуррентное
З десь
k - номер используемой стратегии. Это
уравнение основывается на том, что
суммарный доход rijk + fn+1(j) получается в
результате перехода из состояния i на
этапе n в состояние j на этапе n+1 с
вероятностью pijk.
десь
k - номер используемой стратегии. Это
уравнение основывается на том, что
суммарный доход rijk + fn+1(j) получается в
результате перехода из состояния i на
этапе n в состояние j на этапе n+1 с
вероятностью pijk.
Теперь оптимальное решение можно найти, вычисляя последовательно fn(i) в нисходящем направлении (n = N…1). При этом введение вектора начальных вероятностей в условие задачи не усложнит ее решение.
Данный пример также рассмотрен в .
Моделирование сочетаний слов в тексте
Рассмотрим текст, состоящий из слов w. Представим процесс, в котором состояниями являются слова, так что когда он находится в состоянии (Si) система переходит в состояние (sj) согласно матрице переходных вероятностей. Прежде всего, надо «обучить» систему: подать на вход достаточно большой текст для оценки переходных вероятностей. А затем можно строить траектории марковской цепи. Увеличение смысловой нагрузки текста, построенного при помощи алгоритма цепей Маркова возможно только при увеличении порядка, где состоянием является не одно слово, а множества с большей мощностью - пары (u, v), тройки (u, v, w) и т.д. Причем что в цепях первого, что пятого порядка, смысла будет еще немного. Смысл начнет появляться при увеличении размерности порядка как минимум до среднего количества слов в типовой фразе исходного текста. Но таким путем двигаться нельзя, потому, что рост смысловой нагрузки текста в цепях Маркова высоких порядков происходит значительно медленнее, чем падение уникальности текста. А текст, построенный на марковских цепях, к примеру, тридцатого порядка, все еще будет не настолько осмысленным, чтобы представлять интерес для человека, но уже достаточно схожим с оригинальным текстом, к тому же число состояний в такой цепи будет потрясающим.
Эта технология сейчас очень широко применяется (к сожалению) в Интернете для создания контента веб-страниц. Люди, желающие увеличить трафик на свой сайт и повысить его рейтинг в поисковых системах, стремятся поместить на свои страницы как можно больше ключевых слов для поиска. Но поисковики используют алгоритмы, которые умеют отличать реальный текст от бессвязного нагромождения ключевых слов. Тогда, чтобы обмануть поисковики используют тексты, созданные генератором на основе марковской цепи. Есть, конечно, и положительные примеры использования цепей Маркова для работы с текстом, их применяют при определении авторства, анализе подлинности текстов.
Цепи Маркова и лотереи
В некоторых случаях вероятностная модель используется в прогнозе номеров в различных лотереях. По-видимому, использовать цепи Маркова для моделирования последовательности различных тиражей нет смысла. То, что происходило с шариками в тираже, никак не повлияет на результаты следующего тиража, поскольку после тиража шары собирают, а в следующем тираже их укладывают в лоток лототрона в фиксированном порядке. Связь с прошедшим тиражом при этом теряется. Другое дело последовательность выпадения шаров в пределах одного тиража. В этом случае выпадение очередного шара определяется состоянием лототрона на момент выпадения предыдущего шара. Таким образом, последовательность выпадений шаров в одном тираже является цепью Маркова, и можно использовать такую модель. При анализе числовых лотерей здесь имеется большая трудность. Состояние лототрона после выпадения очередного шара определяет дальнейшие события, но проблема в том, что это состояние нам неизвестно. Все что нам известно, что выпал некоторый шар. Но при выпадении этого шара, остальные шары могут быть расположены различным образом, так что имеется группа из очень большого числа состояний, соответствующая одному и тому же наблюдаемому событию. Поэтому мы можем построить лишь матрицу вероятностей переходов между такими группами состояний. Эти вероятности являются усреднением вероятностей переходов между различными отдельными состояниями, что конечно, снижает эффективность применения модели марковской цепи к числовым лотереям.
Аналогично этому случаю, такая модель нейронной сети может быть использована для предсказания погоды, котировок валют и в связи с другими системами, где есть исторические данные, и в будущем может быть использована вновь поступающая информация. Хорошим применением в данном случае, когда известны только проявления системы, но не внутренние (скрытые) состояния, могут быть применены скрытые марковские модели, которые подробно рассмотрены в Викиучебнике (скрытые марковские модели).
Способы математических описаний марковских случайных процессов в системе с дискретными состояниями (ДС) зависят от того, в какие моменты времени (заранее известные или случайные) могут происходить переходы системы из состояния в состояние.
Если переход системы из состояния в состояние возможен в заранее фиксированные моменты времени, имеем дело со случайным марковским процессом с дискретным временем.
Если переход возможен в любой случайный момент времени, то имеем дело со случайным марковским процессом с непрерывным временем.
Пусть имеется физическая система S
, которая может находиться в n
состояниях S
1 , S
2 , …, S n
. Переходы из состояния в состояние возможны только в моменты времени t
1 , t
2 , …, t k
, назовём эти моменты времени шагами. Будем рассматривать СП в системе S
как функцию целочисленного аргумента 1, 2, …, k
, где аргументом является номер шага.
Пример: S
1 → S
2 → S
3 → S
2 .
Условимся обозначать S i
( k
) – событие, состоящее в том, что после k
шагов система находится в состоянии S i
.
При любом k
события S 1 ( k
) , S 2 ( k
) ,…, S n
( k
) образуют полную группу событий
и являются несовместными.
Процесс в системе можно представить как цепочку событий.
Пример:S
1 (0) , S
2 (1) , S 3 (2) , S 5 (3) ,….
Такая последовательность называется марковской цепью
, если для каждого шага вероятность перехода из любого состояния S i
в любое состояние S j
не зависит от того, когда и как система пришла в состояние S i
.
Пусть в любой момент времени после любого k
-го шага система S
может находиться в одном из состояний S
1 , S
2 , …, S n
, т. е. может произойти одно событие из полной группы событий: S
1 ( k
) , S 2 ( k
) , …, S n
( k
) . Обозначим вероятности этих событий:
P
1 (1) = P
(S
1 (1)); P
2 (1) = P
(S
2 (1)); …; P n
(1) = P
(S n
( k
));
P
1 (2) = P
(S
1 (2)); P
2 (2) = P
(S 2 (2)); …; P n
(2) = P
(S n
(2));
P
1 (k
) = P
(S
1 (k
)); P
2 (k
) = P
(S
2 (k
)); …; P n
(k
) = P
(S n
(k
)).
Легко заметить, что для каждого номера шага выполняется условие
P
1 (k
) + P
2 (k
) +…+ P n
(k
) = 1.
Назовём эти вероятности вероятностями состояний
.следовательно, задача будет звучать следующим образом: найти вероятности состояний системы для любого k
.
Пример.
Пусть имеется какая-то система, которая может находиться в любом из шести состояний. тогда процессы, происходящие в ней, можно изобразить либо в виде графика изменения состояния системы (рис. 7.9, а
), либо в виде графа состояний системы (рис. 7.9, б
).
а) 
Рис. 7.9
Также процессы в системе можно изобразить в виде последовательности состояний: S
1 , S
3 , S
2 , S
2 , S
3 , S
5 , S
6 , S
2 .
Вероятность состояния на (k
+ 1)-м шаге зависит только от состояния на k-
м шаге.
Для любого шага k
существуют какие-то вероятности перехода системы из любого состояния в любое другое состояние, назовем эти вероятности переходными вероятностями марковской цепи.
Некоторые из этих вероятностей будут равны 0, если переход из одного состояния в другое невозможен за один шаг.
Марковская цепь называется однородной
, если переходные состояния не зависят от номера шага, в противном случае она называется неоднородной
.
Пусть имеется однородная марковская цепь и пусть система S
имеет n
возможных состояний: S
1 , …, S n
. Пусть для каждого состояния известна вероятность перехода в другое состояние за один шаг, т. е. P ij
(из S i
в S j
за один шаг), тогда мы можем записать переходные вероятности в виде матрицы.
 . (7.1)
. (7.1)
По диагонали этой матрицы расположены вероятности того, что система переходит из состояния S i
в то же состояние S i
.
Пользуясь введенными ранее событиями ![]() , можно переходные вероятности записать как условные вероятности:
, можно переходные вероятности записать как условные вероятности:
![]() .
.
Очевидно, что сумма членов ![]() в каждой строке матрицы (1) равна единице, поскольку события
в каждой строке матрицы (1) равна единице, поскольку события ![]() образуют полную группу несовместных событий.
образуют полную группу несовместных событий.
При рассмотрении марковских цепей, так же как и при анализе марковского случайного процесса, используются различные графы состояний (рис. 7.10).

Рис. 7.10
Данная система может находиться в любом из шести состояний, при этом P ij
– вероятность перехода системы из состояния S i
в состояние S j
. Для данной системы запишем уравнения, что система находилась в каком-либо состоянии и из него за время t
не вышла:
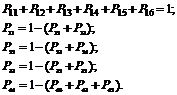
В общем случае марковская цепь является неоднородной, т. е. вероятность P ij
меняется от шага к шагу. Предположим, что задана матрица вероятностей перехода на каждом шаге, тогда вероятность того, что система S
на k
-м шаге будет находиться в состоянии S i
, можно найти по формуле
![]()
Зная матрицу переходных вероятностей и начальное состояние системы, можно найти вероятности состояний ![]() после любого k
-го шага. Пусть в начальный момент времени система находится в состоянии S m
. Тогда для t = 0
после любого k
-го шага. Пусть в начальный момент времени система находится в состоянии S m
. Тогда для t = 0
.
Найдем вероятности после первого шага. Из состояния S m
система перейдет в состояния S
1 , S
2 и т. д. с вероятностями P m
1 , P m
2 , …, P mm
, …, P mn
. Тогда после первого шага вероятности будут равны
. (7.2)
Найдем вероятности состояния после второго шага: . Будем вычислять эти вероятности по формуле полной вероятности с гипотезами:
![]() .
.
Гипотезами будут следующие утверждения:
- после первого шага система была в состоянии S 1 -H 1 ;
- после второго шага система была в состоянии S 2 -H 2 ;
- после n -го шага система была в состоянии S n -H n .
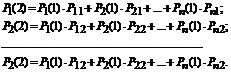
Вероятность любого состояния после второго шага:
![]() (7.3)
(7.3)
В формуле (7.3) суммируются все переходные вероятности P ij
, но учитываются только отличные от нуля. Вероятность любого состояния после k
-го шага:
![]() (7.4)
(7.4)
Таким образом, вероятность состояния после k
-го шага определяется по рекуррентной формуле (7.4) через вероятности (k –
1)-го шага.
Задача 6.
Задана матрица вероятностей перехода для цепи Маркова за один шаг. Найти матрицу перехода данной цепи за три шага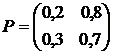 .
.
Решение.
Матрицей перехода системы называют матрицу, которая содержит все переходные вероятности этой системы:
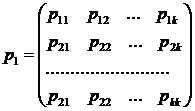
В каждой строке матрицы помещены вероятности событий (перехода из состояния i
в состояние j
), которые образуют полную группу, поэтому сумма вероятностей этих событий равна единице:
![]()
Обозначим через p ij (n) вероятность того, что в результате n шагов (испытаний) система перейдет из состояния i в состояние j . Например p 25 (10) - вероятность перехода из второго состояния в пятое за десять шагов. Отметим, что при n=1 получаем переходные вероятности p ij (1)=p ij .
Перед нами поставлена задача: зная переходные вероятности p ij , найти вероятности p ij (n) перехода системы из состояния i
в состояние j
заn
шагов. Для этого введем промежуточное (между i
и j
) состояние r
. Другими словами, будем считать, что из первоначального состояния i
за m
шагов система перейдет в промежуточное состояние r
с вероятностью p ij (n-m) , после чего, за оставшиеся n-m шагов из промежуточного состояния r она перейдет в конечное состояние j с вероятностью p ij (n-m) . По формуле полной вероятности получаем:
![]() .
.
Эту формулу называют равенством Маркова. С помощью этой формулы можно найти все вероятности p ij (n) , а, следовательно, и саму матрицу P n . Так как матричное исчисление ведет к цели быстрее, запишем вытекающее из полученной формулы матричное соотношение в общем виде.
Вычислим матрицу перехода цепи Маркова за три шага, используя полученную формулу:
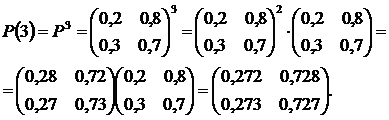
Ответ:
 .
.
Задача №1
. Матрица вероятностей перехода цепи Маркова имеет вид:
 .
.
Распределение по состояниям в момент времени t=0 определяется вектором:
π 0 =(0.5; 0.2; 0.3)
Найти:
а) распределение по состояниям в моменты t=1,2,3,4 .
в) стационарное распределение.
Цепь Маркова – череда событий, в которой каждое последующее событие зависит от предыдущего. В статье мы подробнее разберём это понятие.
Цепь Маркова – это распространенный и довольно простой способ моделирования случайных событий. Используется в самых разных областях, начиная генерацией текста и заканчивая финансовым моделированием. Самым известным примером является SubredditSimulator . В данном случае Цепь Маркова используется для автоматизации создания контента во всем subreddit.
Цепь Маркова понятна и проста в использовании, т. к. она может быть реализована без использования каких-либо статистических или математических концепций. Цепь Маркова идеально подходит для изучения вероятностного моделирования и Data Science.
Сценарий
Представьте, что существует только два погодных условия: может быть либо солнечно, либо пасмурно. Всегда можно безошибочно определить погоду в текущий момент. Гарантированно будет ясно или облачно.
Теперь вам захотелось научиться предсказывать погоду на завтрашний день. Интуитивно вы понимаете, что погода не может кардинально поменяться за один день. На это влияет множество факторов. Завтрашняя погода напрямую зависит от текущей и т. д. Таким образом, для того чтобы предсказывать погоду, вы на протяжении нескольких лет собираете данные и приходите к выводу, что после пасмурного дня вероятность солнечного равна 0,25. Логично предположить, что вероятность двух пасмурных дней подряд равна 0,75, так как мы имеем всего два возможных погодных условия.

Теперь вы можете прогнозировать погоду на несколько дней вперед, основываясь на текущей погоде.
Этот пример показывает ключевые понятия цепи Маркова. Цепь Маркова состоит из набора переходов, которые определяются распределением вероятностей, которые в свою очередь удовлетворяют Марковскому свойству.
Обратите внимание, что в примере распределение вероятностей зависит только от переходов с текущего дня на следующий. Это уникальное свойство Марковского процесса – он делает это без использования памяти. Как правило, такой подход не способен создать последовательность, в которой бы наблюдалась какая-либо тенденция. Например, в то время как цепь Маркова способна сымитировать стиль письма, основанный на частоте использования какого-то слова, она не способна создать тексты с глубоким смыслом, так как она может работать только с большими текстами. Именно поэтому цепь Маркова не может производить контент, зависящий от контекста.
Модель
Формально, цепь Маркова – это вероятностный автомат. Распределение вероятностей переходов обычно представляется в виде матрицы. Если цепь Маркова имеет N возможных состояний, то матрица будет иметь вид N x N, в которой запись (I, J) будет являться вероятностью перехода из состояния I в состояние J. Кроме того, такая матрица должна быть стохастической, то есть строки или столбцы в сумме должны давать единицу. В такой матрице каждая строка будет иметь собственное распределение вероятностей.

Общий вид цепи Маркова с состояниями в виде окружностей и ребрами в виде переходов.

Примерная матрица перехода с тремя возможными состояниями.
Цепь Маркова имеет начальный вектор состояния, представленный в виде матрицы N x 1. Он описывает распределения вероятностей начала в каждом из N возможных состояний. Запись I описывает вероятность начала цепи в состоянии I.
Этих двух структур вполне хватит для представления цепи Маркова.
Мы уже обсудили, как получить вероятность перехода из одного состояния в другое, но что насчет получения этой вероятности за несколько шагов? Для этого нам необходимо определить вероятность перехода из состояния I в состояние J за M шагов. На самом деле это очень просто. Матрицу перехода P можно определить вычислением (I, J) с помощью возведения P в степень M. Для малых значений M это можно делать вручную, с помощью повторного умножения. Но для больших значений M, если вы знакомы с линейной алгеброй, более эффективным способом возведения матрицы в степень будет сначала диагонализировать эту матрицу.
Цепь Маркова: заключение
Теперь, зная, что из себя представляет цепь Маркова, вы можете легко реализовать её на одном из языков программирования. Простые цепи Маркова являются фундаментом для изучения более сложных методов моделирования.
по себе, а отчасти рассматриваем мы ее из-за того, что ее изложение не требует введения большого количества новых терминов.Рассмотрим задачу об осле, стоящем точно между двумя копнами: соломы ржи и соломы пшеницы (рис. 10.5).
Осел стоит между двумя копнами: "Рожь" и "Пшеница" (рис. 10.5). Каждую минуту он либо передвигается на десять метров в сторону первой копны (с вероятностью ), либо в сторону второй копны (с вероятностью ), либо остается там, где стоял (с вероятностью ); такое поведение называется одномерным случайным блужданием. Будем предполагать, что обе копны являются "поглощающими" в том смысле, что если осел подойдет к одной из копен, то он там и останется. Зная расстояние между двумя копнами и начальное положение осла, можно поставить несколько вопросов, например: у какой копны он очутится с большей вероятностью и какое наиболее вероятное время ему понадобится, чтобы попасть туда?

Рис. 10.5.
Чтобы исследовать эту задачу подробнее, предположим, что расстояние
между
копнами равно пятидесяти метрам и что наш осел находится в двадцати метрах
от копны "Пшеницы". Если места, где можно остановиться, обозначить
через ![]() ( - сами
копны), то его начальное положение можно задать вектором -я
компонента которого равна вероятности того, что он первоначально находится
в . Далее, по
прошествии одной минуты вероятности его
местоположения описываются вектором , а через
две минуты - вектором . Ясно, что
непосредственное вычисление
вероятности его нахождения в заданном месте по
прошествии минут становится затруднительным. Оказалось, что
удобнее всего ввести для этого матрицу перехода
.
( - сами
копны), то его начальное положение можно задать вектором -я
компонента которого равна вероятности того, что он первоначально находится
в . Далее, по
прошествии одной минуты вероятности его
местоположения описываются вектором , а через
две минуты - вектором . Ясно, что
непосредственное вычисление
вероятности его нахождения в заданном месте по
прошествии минут становится затруднительным. Оказалось, что
удобнее всего ввести для этого матрицу перехода
.

Пусть - вероятность того, что он переместится из в за одну минуту. Например, и . Эти вероятности называются вероятностями перехода , а -матрицу называют матрицей перехода . Заметим, что каждый элемент матрицы неотрицателен и что сумма элементов любой из строк равна единице. Из всего этого следует, что - начальный вектор -строка, определенный выше, местоположение осла по прошествии одной минуты описывается вектором-строкой , а после минут - вектором . Другими словами, -я компонента вектора определяет вероятность того, что по истечении минут осел оказался в .
Можно обобщить эти понятия. Назовем вектором вероятностей вектор -строку, все компоненты которого неотрицательны и дают в сумме единицу. Тогда матрица перехода определяется как квадратная матрица , в которой каждая строка является вектором вероятностей. Теперь можно определить цепь Маркова (или просто цепь) как пару , где есть - матрица перехода , а есть - вектор -строка. Если каждый элемент из рассматривать как вероятность перехода из позиции в позицию , а - как начальный вектор вероятностей, то придем к классическому понятию дискретной стационарной цепи Маркова , которое можно найти в книгах по теории вероятностей (см. Феллер В. Введение в теорию вероятностей и ее приложения. Т.1. М.: Мир. 1967) Позиция обычно называется состоянием цепи . Опишем различные способы их классификации.
Нас будет интересовать следующее: можно ли попасть из одного данного состояния в другое, и если да, то за какое наименьшее время. Например, в задаче об осле из в можно попасть за три минуты и вообще нельзя попасть из в . Следовательно, в основном мы будем интересоваться не самими вероятностями , а тем, положительны они или нет. Тогда появляется надежда, что все эти данные удастся представить в виде орграфа , вершины которого соответствуют состояниям, а дуги указывают на то, можно ли перейти из одного состояния в другое за одну минуту. Более точно, если каждое состояние представлено соответствующей ему вершиной).
Эта статья дает общее представление о том, как генерировать тексты при помощи моделирования марковских процессов. В частности, мы познакомимся с цепями Маркова, а в качестве практики реализуем небольшой генератор текста на Python.
Для начала выпишем нужные, но пока не очень понятные нам определения со страницы в Википедии , чтобы хотя бы примерно представлять, с чем мы имеем дело:
Марковский процесс t t
Марковская цепь
Что все это значит? Давайте разбираться.
Основы
Первый пример предельно прост. Используя предложение из детской книжки , мы освоим базовую концепцию цепи Маркова, а также определим, что такое в нашем контексте корпус, звенья, распределение вероятностей и гистограммы . Несмотря на то, что предложение приведено на английском языке, суть теории будет легко уловить.
Это предложение и есть корпус , то есть база, на основе которой в дальнейшем будет генерироваться текст. Оно состоит из восьми слов, но при этом уникальных слов только пять - это звенья (мы ведь говорим о марковской цепи ). Для наглядности окрасим каждое звено в свой цвет:

И выпишем количество появлений каждого из звеньев в тексте:

На картинке выше видно, что слово «fish» появляется в тексте в 4 раза чаще, чем каждое из других слов («One», «two», «red», «blue» ). То есть вероятность встретить в нашем корпусе слово «fish» в 4 раза выше, чем вероятность встретить каждое другое слово из приведенных на рисунке. Говоря на языке математики, мы можем определить закон распределения случайной величины и вычислить, с какой вероятностью одно из слов появится в тексте после текущего. Вероятность считается так: нужно разделить число появлений нужного нам слова в корпусе на общее число всех слов в нем. Для слова «fish» эта вероятность - 50%, так как оно появляется 4 раза в предложении из 8 слов. Для каждого из остальных звеньев эта вероятность равна 12,5% (1/8).
Графически представить распределение случайных величин можно с помощью гистограммы . В данном случае, наглядно видна частота появления каждого из звеньев в предложении:

Итак, наш текст состоит из слов и уникальных звеньев, а распределение вероятностей появления каждого из звеньев в предложении мы отобразили на гистограмме. Если вам кажется, что возиться со статистикой не стоит, прочитайте . И, возможно, сохранит вам жизнь.
Суть определения
Теперь добавим к нашему тексту элементы, которые всегда подразумеваются, но не озвучиваются в повседневной речи - начало и конец предложения:

Любое предложение содержит эти невидимые «начало» и «конец», добавим их в качестве звеньев к нашему распределению:

Вернемся к определению, данному в начале статьи:
Марковский процесс - случайный процесс, эволюция которого после любого заданного значения временного параметра t не зависит от эволюции, предшествовавшей t , при условии, что значение процесса в этот момент фиксировано.
Марковская цепь - частный случай марковского процесса, когда пространство его состояний дискретно (т.е. не более чем счетно).
Так что же это значит? Грубо говоря, мы моделируем процесс, в котором состояние системы в следующий момент времени зависит только от её состояния в текущий момент, и никак не зависит от всех предыдущих состояний .
Представьте, что перед вами окно , которое отображает только текущее состояние системы (в нашем случае, это одно слово), и вам нужно определить, каким будет следующее слово, основываясь только на данных, представленных в этом окне. В нашем корпусе слова следуют одно за другим по такой схеме:

Таким образом, формируются пары слов (даже у конца предложения есть своя пара - пустое значение):

Сгруппируем эти пары по первому слову. Мы увидим, что у каждого слова есть свой набор звеньев, которые в контексте нашего предложения могут за ним следовать:

Представим эту информацию другим способом - каждому звену поставим в соответствие массив из всех слов, которые могут появиться в тексте после этого звена:

Разберем подробнее. Мы видим, что у каждого звена есть слова, которые могут стоять после него в предложении. Если бы мы показали схему выше кому-то еще, этот человек с некоторой вероятностью мог бы реконструировать наше начальное предложение, то есть корпус.
Пример. Начнем со слова «Start» . Далее выбираем слово «One» , так как по нашей схеме это единственное слово, которое может следовать за началом предложения. За словом «One» тоже может следовать только одно слово - «fish» . Теперь новое предложение в промежуточном варианте выглядит как «One fish» . Дальше ситуация усложняется - за «fish» могут с равной вероятностью в 25% идти слова «two», «red», «blue» и конец предложения «End» . Если мы предположим, что следующее слово - «two» , реконструкция продолжится. Но мы можем выбрать и звено «End» . В таком случае на основе нашей схемы будет случайно сгенерировано предложение, сильно отличающееся от корпуса - «One fish» .
Мы только что смоделировали марковский процесс - определили каждое следующее слово только на основании знаний о текущем. Давайте для полного усвоения материала построим диаграммы, отображающие зависимости между элементами внутри нашего корпуса. Овалы представляют собой звенья. Стрелки ведут к потенциальным звеньям, которые могут идти за словом в овале. Около каждой стрелки - вероятность, с которой следующее звено появится после текущего:

Отлично! Мы усвоили необходимую информацию, чтобы двигаться дальше и разбирать более сложные модели.
Расширяем словарную базу
В этой части статьи мы будем строить модель по тому же принципу, что и раньше, но при описании опустим некоторые шаги. Если возникнут затруднения, возвращайтесь к теории в первом блоке.
Возьмем еще четыре цитаты того же автора (также на английском, нам это не помешает):
«Today you are you. That is truer than true. There is no one alive who is you-er than you.»
«You have brains in your head. You have feet in your shoes. You can steer yourself any direction you choose. You’re on your own.»
«The more that you read, the more things you will know. The more that you learn, the more places you’ll go.»
«Think left and think right and think low and think high. Oh, the thinks you can think up if only you try.»
Сложность корпуса увеличилась, но в нашем случае это только плюс - теперь генератор текста сможет выдавать более осмысленные предложения. Дело в том, что в любом языке есть слова, которые встречаются в речи чаще, чем другие (например, предлог «в» мы используем гораздо чаще, чем слово «криогенный»). Чем больше слов в нашем корпусе (а значит, и зависимостей между ними), тем больше у генератора информации о том, какое слово вероятнее всего должно появиться в тексте после текущего.
Проще всего это объясняется с точки зрения программы. Мы знаем, что для каждого звена существует набор слов, которые могут за ним следовать. А также, каждое слово характеризуется числом его появлений в тексте. Нам нужно каким-то образом зафиксировать всю эту информацию в одном месте; для этой цели лучше всего подойдет словарь, хранящий пары «(ключ, значение)». В ключе словаря будет записано текущее состояние системы, то есть одно из звеньев корпуса (например, «the» на картинке ниже); а в значении словаря будет храниться еще один словарь. Во вложенном словаре ключами будут слова, которые могут идти в тексте после текущего звена корпуса («thinks» и «more» могут идти в тексте после «the» ), а значениями - число появлений этих слов в тексте после нашего звена (слово «thinks» появляется в тексте после слова «the» 1 раз, слово «more» после слова «the» - 4 раза):

Перечитайте абзац выше несколько раз, чтобы точно разобраться. Обратите внимание, что вложенный словарь в данном случае - это та же гистограмма, он помогает нам отслеживать звенья и частоту их появления в тексте относительно других слов. Надо заметить, что даже такая словарная база очень мала для надлежащей генерации текстов на естественном языке - она должна содержать более 20 000 слов, а лучше более 100 000. А еще лучше - более 500 000. Но давайте рассмотрим ту словарную базу, которая получилась у нас.
Цепь Маркова в данном случае строится аналогично первому примеру - каждое следующее слово выбирается только на основании знаний о текущем слове, все остальные слова не учитываются. Но благодаря хранению в словаре данных о том, какие слова появляются чаще других, мы можем при выборе принять взвешенное решение . Давайте разберем конкретный пример:
More:
То есть если текущим словом является слово «more» , после него могут с равной вероятностью в 25% идти слова «things» и «places» , и с вероятностью 50% - слово «that» . Но вероятности могут быть и все равны между собой:
Think:
Работа с окнами
До настоящего момента мы с вами рассматривали только окна размером в одно слово. Можно увеличить размер окна, чтобы генератор текста выдавал более «выверенные» предложения. Это значит, что чем больше окно, тем меньше будет отклонений от корпуса при генерации. Увеличение размера окна соответствует переходу цепи Маркова к более высокому порядку. Ранее мы строили цепь первого порядка, для окна из двух слов получится цепь второго порядка, из трех - третьего, и так далее.
Окно - это те данные в текущем состоянии системы, которые используются для принятия решений. Если мы совместим большое окно и маленький набор данных, то, скорее всего, каждый раз будем получать одно и то же предложение. Давайте возьмем словарную базу из нашего первого примера и расширим окно до размера 2:

Расширение привело к тому, что у каждого окна теперь только один вариант следующего состояния системы - что бы мы ни делали, мы всегда будем получать одно и то же предложение, идентичное нашему корпусу. Поэтому, чтобы экспериментировать с окнами, и чтобы генератор текста возвращал уникальный контент, запаситесь словарной базой от 500 000 слов.
Реализация на Python
Структура данных Dictogram
Dictogram (dict - встроенный тип данных словарь в Python) будет отображать зависимость между звеньями и их частотой появления в тексте, то есть их распределение. Но при этом она будет обладать нужным нам свойством словаря - время выполнения программы не будет зависеть от объема входных данных, а это значит, мы создаем эффективный алгоритм.
Import random class Dictogram(dict): def __init__(self, iterable=None): # Инициализируем наше распределение как новый объект класса, # добавляем имеющиеся элементы super(Dictogram, self).__init__() self.types = 0 # число уникальных ключей в распределении self.tokens = 0 # общее количество всех слов в распределении if iterable: self.update(iterable) def update(self, iterable): # Обновляем распределение элементами из имеющегося # итерируемого набора данных for item in iterable: if item in self: self += 1 self.tokens += 1 else: self = 1 self.types += 1 self.tokens += 1 def count(self, item): # Возвращаем значение счетчика элемента, или 0 if item in self: return self return 0 def return_random_word(self): random_key = random.sample(self, 1) # Другой способ: # random.choice(histogram.keys()) return random_key def return_weighted_random_word(self): # Сгенерировать псевдослучайное число между 0 и (n-1), # где n - общее число слов random_int = random.randint(0, self.tokens-1) index = 0 list_of_keys = self.keys() # вывести "случайный индекс:", random_int for i in range(0, self.types): index += self] # вывести индекс if(index > random_int): # вывести list_of_keys[i] return list_of_keys[i]
В конструктор структуре Dictogram можно передать любой объект, по которому можно итерироваться. Элементами этого объекта будут слова для инициализации Dictogram, например, все слова из какой-нибудь книги. В данном случае мы ведем подсчет элементов, чтобы для обращения к какому-либо из них не нужно было пробегать каждый раз по всему набору данных.
Мы также сделали две функции для возврата случайного слова. Одна функция выбирает случайный ключ в словаре, а другая, принимая во внимание число появлений каждого слова в тексте, возвращает нужное нам слово.
Структура цепи Маркова
from histograms import Dictogram def make_markov_model(data): markov_model = dict() for i in range(0, len(data)-1): if data[i] in markov_model: # Просто присоединяем к уже существующему распределению markov_model].update(]) else: markov_model] = Dictogram(]) return markov_modelВ реализации выше у нас есть словарь, который хранит окна в качестве ключа в паре «(ключ, значение)» и распределения в качестве значений в этой паре.
Структура цепи Маркова N-го порядка
from histograms import Dictogram def make_higher_order_markov_model(order, data): markov_model = dict() for i in range(0, len(data)-order): # Создаем окно window = tuple(data) # Добавляем в словарь if window in markov_model: # Присоединяем к уже существующему распределению markov_model.update(]) else: markov_model = Dictogram(]) return markov_modelОчень похоже на цепь Маркова первого порядка, но в данном случае мы храним кортеж в качестве ключа в паре «(ключ, значение)» в словаре. Мы используем его вместо списка, так как кортеж защищен от любых изменений, а для нас это важно - ведь ключи в словаре меняться не должны.
Парсинг модели
Отлично, мы реализовали словарь. Но как теперь совершить генерацию контента, основываясь на текущем состоянии и шаге к следующему состоянию? Пройдемся по нашей модели:
From histograms import Dictogram import random from collections import deque import re def generate_random_start(model): # Чтобы сгенерировать любое начальное слово, раскомментируйте строку: # return random.choice(model.keys()) # Чтобы сгенерировать "правильное" начальное слово, используйте код ниже: # Правильные начальные слова - это те, что являлись началом предложений в корпусе if "END" in model: seed_word = "END" while seed_word == "END": seed_word = model["END"].return_weighted_random_word() return seed_word return random.choice(model.keys()) def generate_random_sentence(length, markov_model): current_word = generate_random_start(markov_model) sentence = for i in range(0, length): current_dictogram = markov_model random_weighted_word = current_dictogram.return_weighted_random_word() current_word = random_weighted_word sentence.append(current_word) sentence = sentence.capitalize() return " ".join(sentence) + "." return sentence
Что дальше?
Попробуйте придумать, где вы сами можете использовать генератор текста на основе марковских цепей. Только не забывайте, что самое главное — это то, как вы парсите модель и какие особые ограничения устанавливаете на генерацию. Автор этой статьи, например, при создании генератора твитов использовал большое окно, ограничил генерируемый контент до 140 символов и использовал для начала предложений только «правильные» слова, то есть те, которые являлись началом предложений в корпусе.