Медиана математическая статистика. Как появилось понятие о среднем значении? Мода и ее практическое значение
Функция МЕДИАНА в Excel используется для анализа диапазона числовых значений и возвращает число, которое является серединой исследуемого множества (медианой). То есть, данная функция условно разделяет множество чисел на два подмножества, первое из которых содержит числа меньше медианы, а второе – больше. Медиана является одним из нескольких методов определения центральной тенденции исследуемого диапазона.
Примеры использования функции МЕДИАНА в Excel
При исследовании возрастных групп студентов использовались данные случайно выбранной группы учащихся в ВУЗе. Задача – определить срединный возраст студентов.
Исходные данные:
Формула для расчета:
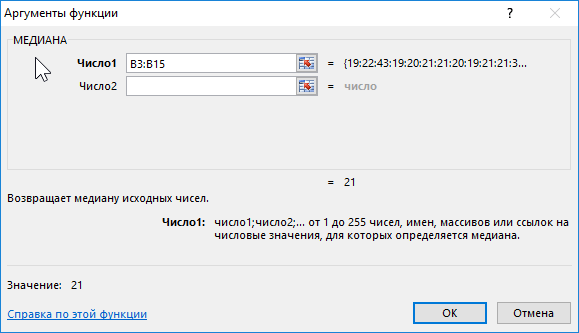
Описание аргумента:
- B3:B15 – диапазон исследуемых возрастов.
Полученный результат:

То есть в группе есть студенты, возраст которых меньше 21 года и больше этого значения.
Сравнение функций МЕДИАНА и СРЗНАЧ для вычисления среднего значения
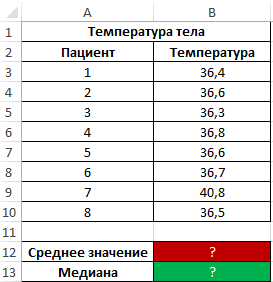
Во время вечернего обхода в больнице каждому больному была замерена температура тела. Продемонстрировать целесообразность использования параметра медиана вместо среднего значения для исследования ряда полученных значений.
Исходные данные:
Формула для нахождения среднего значения:

Формула для нахождения медианы:

Как видно из показателя среднего значения, в среднем температура у пациентов выше нормы, однако это не соответствует действительности. Медиана показывает, что как минимум у половины пациентов наблюдается нормальная температура тела, не превышающая показатель 36,6.
Внимание! Еще одним методом определения центральной тенденции является мода (наиболее часто встречающееся значение в исследуемом диапазоне). Чтобы определить центральную тенденцию в Excel следует использовать функцию МОДА. Обратите внимание: в данном примере значения медианы и моды совпадают:

То есть срединная величина, делящая одно множество на подмножества меньших и больших значений также является и наиболее часто встречающимся значением в множестве. Как видно, у большинства пациентов температура составляет 36,6.
Пример расчета медианы при статистическом анализе в Excel
Пример 3. В магазине работают 3 продавца. По результатам последних 10 дней необходимо определить работника, которому будет выдана премия. При выборе лучшего работника учитывается степень эффективности его работы, а не число проданных товаров.
Исходная таблица данных:

Для характеристики эффективности будем использовать сразу три показателя: среднее значение, медиана и мода. Определим их для каждого работника с использованием формул СРЗНАЧ, МЕДИАНА и МОДА соответственно:

Для определения степени разброса данных используем величину, которая является суммарным значением модуля разницы среднего значения и моды, среднего значения и медианы соответственно. То есть коэффициент x=|av-med|+|av-mod|, где:
- av – среднее значение;
- med – медиана;
- mod – мода.
Рассчитаем значение коэффициента x для первого продавца:
Аналогично проведем расчеты для остальных продавцов. Полученные результаты:

Определим продавца, которому будет выдана премия:
Примечание: функция НАИМЕНЬШИЙ возвращает первое минимальное значение из рассматриваемого диапазона значений коэффициента x.

Коэффициент x является некоторой количественной характеристикой стабильности работы продавцов, которую ввел экономист магазина. С его помощью удалось определить диапазон с наименьшими отклонениями значений. Этот способ демонстрирует, как можно использовать сразу три метода определения центральной тенденции для получения наиболее достоверных результатов.
Особенности использования функции МЕДИАНА в Excel
Функция имеет следующий синтаксис:
МЕДИАНА(число1; [число2];...)
Описание аргументов:
- число1 – обязательный аргумент, характеризующий первое числовое значение, содержащееся в исследуемом диапазоне;
- [число2] – необязательный второй (и последующие аргументы, всего до 255 аргументов), характеризующий второе и последующие значения исследуемого диапазона.
Примечания 1:
- При расчетах удобнее передавать сразу весь диапазон исследуемых значений вместо последовательного ввода аргументов.
- В качестве аргументов принимаются данные числового типа, имена, содержащие числа, данные ссылочного типа и массивы (например, =МЕДИАНА({1;2;3;5;7;10})).
- При расчете медианы учитываются ячейки, содержащие пустые значения или логические ИСТИНА, ЛОЖЬ, которые будут интерпретированы как числовые значения 1 и 0 соответственно. Например, результат выполнения функции с логическими значениями в аргументах (ИСТИНА;ЛОЖЬ) эквивалентен результату выполнения с аргументами (1;0) и равен 0,5.
- Если один или несколько аргументов функции принимают текстовые значения, которые не могут быть преобразованы в числовые, или содержат коды ошибок, результатом выполнения функции будет код ошибки #ЗНАЧ!.
- Для определения медианы выборки могут быть использованы другие функции Excel: ПРОЦЕНТИЛЬ.ВКЛ, КВАРТИЛЬ.ВКЛ, НАИБОЛЬШИЙ Примеры использования:
- =ПРОЦЕНТИЛЬ.ВКЛ(A1:A10;0,5), поскольку по определению медиана – 50-я процентиль.
- =КВАРТИЛЬ.ВКЛ(A1:A10;2), так как медиана – 2-я квартиль.
- =НАИБОЛЬШИЙ(A1:A9;СЧЁТ(A1:A9)/2), но только если количество чисел в диапазоне является нечетным числом.
Примечания 2:
- Если в исследуемом диапазоне все числа распределены симметрично относительно среднего значения, среднее арифметическое и медиана для данного диапазона будут эквивалентны.
- При больших отклонениях данных в диапазоне («разбросе» значений) медиана лучше отражает тенденцию распределения значений, чем среднее арифметическое. Отличным примером является использование медианы для определения реального уровня зарплат у населения государства, в котором чиновники получают на порядок больше обычных граждан.
- Диапазон исследуемых значений может содержать:
- Нечетное количество чисел. В этом случае медианой будет являться единственное число, разделяющее диапазон на два подмножества больших и меньших значений соответственно;
- Четное количество чисел. Тогда медиана вычисляется как среднее арифметическое для двух числовых значений, разделяющих множество на два указанных выше подмножества.
4. Мода. Медиана. Генеральная и выборочная средняя
Мода на экране, медиана в треугольнике, а средние – это температура по больнице и в палате. Продолжаем наш практический курс занимательной статистики (Занятие 1) изучением центральных характеристик статистической совокупности , названия которых вы видите в заголовке. И начнём мы с его конца, поскольку о средних величинах речь зашла практически с первых же абзацев темы. Для подготовленных читателей оглавление :
- Генеральная и выборочная средняя – вычисление по первичным данным и для сформированного дискретного вариационного ряда;
- Мода – определение и нахождение для дискретного случая;
- Медиана – общее определение, как найти медиану;
- Средняя, мода и медиана интервального вариационного ряда – вычисление по первичным данным и по готовому ряду. Формулы моды и медианы,
- Квартили, децили, перцентили – коротко о главном.
ну а «чайникам» лучше ознакомиться с материалом по порядку:
Итак, пусть исследуется некоторая генеральная совокупность объёма , а именно её числовая характеристика , не важно, дискретная или непрерывная (Занятия 2, 3 ).
Генеральной средней
называется среднее арифметическое
всех значений этой совокупности:
Если среди чисел есть одинаковые (что характерно для дискретного ряда
)
, то формулу можно записать в более компактном виде: , где
, где
варианта
повторяется раз;
варианта – раз;
варианта – раз;
…
варианта – раз.
Живой пример вычисления генеральной средней встретился в Примере 2 , но чтобы не занудничать, я даже не буду напоминать его содержание.
Далее. Как мы помним, обработка всей генеральной совокупности часто затруднена либо невозможна, и поэтому из неё организуют представительную выборку объема , и на основании исследования этой выборки делают вывод обо всей совокупности.
Выборочной средней
называется среднее арифметическое
всех значений выборки:
и при наличии одинаковых вариант формула запишется компактнее: – как сумма произведений вариант на соответствующие частоты
.
– как сумма произведений вариант на соответствующие частоты
.
Выборочная средняя позволяет достаточно точно оценить истинное значение , чего вполне достаточно для многих исследований. При этом, чем больше выборка, тем точнее будет эта оценка.
Практику начнём, а точнее продолжим, с дискретного вариационного ряда и знакомого условия:
Пример 8
По результатам выборочного исследования рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4, 4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3.
Как решать
задачу? Если нам даны первичные данные
(исходные необработанные значения), то их можно тупо просуммировать и разделить результат на объём выборки:
– среднестатистический квалификационный разряд рабочих цеха.
Но во многих задачах требуется составить вариационный ряд (см. Пример 4
)
:
– или же этот ряд предложен изначально (что бывает чаще). И тогда, мы, конечно, используем «цивилизованную» формулу:
Мода
. Мода дискретного вариационного ряда – это варианта
с максимальной частотой. В данном случае . Моду легко отыскать по таблице, и ещё легче на полигоне частот
– это абсцисса самой высокой точки:
Иногда таковых значений несколько (с одинаковой максимальной частотой), и тогда модой считают каждое из них.
Если все или почти все варианты различны (что характерно для интервального ряда ), то модальное значение определяется несколько другим способом, о котором во 2-й части урока.
Медиана . Медиана вариационного ряда* – это значение, которая делит его на две равные части (по количеству вариант).
Но теперь нам нужно найти среднюю, моду и медиану.
Решение
: чтобы найти среднюю
по первичным данным, лучше всего просуммировать все варианты и разделить полученный результат на объём совокупности:
ден. ед.
Эти подсчёты, кстати, займут не так много времени и при использовании оффлайн калькулятора. Но если есть Эксель, то, конечно, забиваем в любую свободную ячейку =СУММ(, выделяем мышкой все числа, закрываем скобку ) , ставим знак деления / , вводим число 30 и жмём Enter . Готово.
Что касается моды, то её оценка по исходным данным, становится непригодна. Хоть мы и видим среди чисел одинаковые, но среди них запросто может найтись пять так шесть-семь вариант с одинаковой максимальной частотой, например, частотой 2. Кроме того, цены могут быть округлёнными. Поэтому модальное значение рассчитывается по сформированному интервальному ряду (о чём чуть позже) .
Чего не скажешь о медиане: забиваем в Эксель =МЕДИАНА(, выделяем мышью все числа, закрываем скобку ) и жмём Enter : . Причём, здесь даже ничего не нужно сортировать.
Но в Примере 6 была проведена сортировка по возрастанию (вспоминаем и сортируем – ссылка выше) , и это хорошая возможность повторить формальный алгоритм отыскания медианы. Делим объём выборки пополам:
И поскольку она состоит из чётного количества вариант, то медиана равна среднему арифметическому 15-й и 16-й варианты упорядоченного (!) вариационного ряда:
![]() ден. ед.
ден. ед.
Ситуация вторая . Когда дан готовый интервальный ряд (типичная учебная задача).
Продолжаем анализировать тот же пример с ботинками, где по исходным данным был составлен ИВР
. Для вычисления средней
потребуются середины интервалов:
– чтобы воспользоваться знакомой формулой дискретного случая:
– отличный результат! Расхождение с более точным значением (), вычисленным по первичным данным, составляет всего 0,04.
По сути дела, здесь мы приблизили интервальный ряд дискретным, и это приближение оказалось весьма эффективным. Впрочем, особой выгоды тут нет, т.к. при современном программном обеспечении не составляет труда вычислить точное значение даже по очень большому массиву первичных данных. Но это при условии, что они нам известны:)
С другими центральными показателями всё занятнее.
Чтобы найти моду, нужно найти модальный интервал
(с максимальной частотой)
– в данной задаче это интервал с частотой 11, и воспользоваться следующей страшненькой формулой:![]() , где:
, где:
– нижняя граница модального интервала;![]() – длина модального интервала;
– длина модального интервала;
– частота модального интервала;
– частота предыдущего интервала;
– частота следующего интервала.
Таким образом:
ден. ед. – как видите, «модная» цена на ботинки заметно отличается от средней арифметической .
Не вдаваясь в геометрию формулы, просто приведу гистограмму относительных частот
и отмечу :
откуда хорошо видно, что мода смещена относительно центра модального интервала в сторону левого интервала с бОльшей частотой. Логично.
Справочно разберу редкие случаи:
– если модальный интервал крайний, то либо ;
– если обнаружатся 2 модальных интервала, которые находятся рядом, например, и , то рассматриваем модальный интервал , при этом близлежащие интервалы (слева и справа) по возможности тоже укрупняем в 2 раза.
– если между модальными интервалами есть расстояние, то применяем формулу к каждому интервалу, получая тем самым 2 или бОльшее количество мод.
Вот такой вот депеш мод:)
И медиана. Если дан готовый интервальный ряд, то медиана рассчитывается чуть по менее страшной формуле, но сначала нудно (описка по Фрейду:)) найти медианный интервал – это интервал, содержащий варианту (либо 2 варианты), которая делит вариационный ряд на две равные части.
Выше я рассказал, как определить медиану, ориентируясь на относительные накопленные частоты
, здесь же сподручнее рассчитать «обычные» накопленные частоты . Вычислительный алгоритм точно такой же – первое значение сносим слева (красная стрелка)
, и каждое следующее получается как сумма предыдущего с текущей частотой из левого столбца (зелёные обозначения в качестве примера)
:
Всем понятен смысл чисел в правом столбце? – это количество вариант, которые успели «накопиться» на всех «пройденных» интервалах, включая текущий.
Поскольку у нас чётное количество вариант (30 штук), то медианным будет тот интервал, который содержит 30/2 = 15-ю и 16-ю варианту. И ориентируясь по накопленным частотам, легко прийти к выводу, что эти варианты содержатся в интервале .
Формула медианы:![]() , где:
, где:
– объём статистической совокупности;
– нижняя граница медианного интервала;![]() – длина медианного интервала;
– длина медианного интервала;
– частота
медианного интервала;
– накопленная частота
предыдущего
интервала.
Таким образом:
ден. ед. – заметим, что медианное значение, наоборот, оказалось смещено правее, т.к. по правую руку находится значительное количество вариант:
И справочно особые случаи.
Медиана (Me) – значение признака, приходящееся на середину ранжированного ряда, т.е. делящее ряд распределения на две равные части.
а) для ряда одиночных значений:
Если нечетное кол-во вариант, то серединное значение в ранжированном ряду
Если четное , то сред.арифмет. из 2х смежных серединных значений в ранжиров. ряду
б) В дискретном ряду распределения определяется номер медианы по формуле:
Номер медианы показывает то значение показателя, которое и является медианой.
в) В интервальном ряду распределения медиана рассчитывается по следующей формуле:

x - нижняя граница медианного интервала;
i - величина интервала;
f - численность медианного интервала;
S - сумма накопленных частот интервалов, предшествующих медианному.
31. Мода и ее практическое значение
Мода (Mo) – величина признака, наиболее часто встречающаяся в совокупности, т.е. имеющая наибольшую численность в ряду распределения.
а) В дискретном ряду распределения мода определяется визуально.
б) В интервальном ряду распределения визуально можно определить только интервал, в котором заключена мода, который называется модальным интервалом(тот, который имеет наибольшую частоту).
Мода будет равна:
x - нижняя граница модального интервала;
i - величина интервала;
f - численность модального интервала;
Если все значения вариационного ряда имеют одинаковую частоту, то говорят, что этот вариационный ряд не имеет моды. Если две не соседних варианты имеют одинаковую доминирующую частоту, то такой вариационный ряд называют бимодальным ; если таких вариант больше двух, то ряд – полимодальный .
32. Показатели вариации и способы их расчета
Вариации – колеблемость, многообразие, изменяемость величины признака у единиц совокупности.
Показатели вариации делятся на абсолютные и относительные.
К абсолютным показателям относятся размах вариации, среднее линейное отклонение, дисперсия, среднее квадратическое отклонение. К относительным – коэффициенты осцилляции, коэффициенты вариации и относительное линейное отклонение.
Размах
вариации
– простейший показатель, разность между
максимальным и минимальным значениями
признака.

Недостатком является то, что он оценивает только границы варьирования признака и не отражает его колеблемость внутри этих границ.
Среднее линейное отклонение отражает все колебания варьирующего признака и представляет собой среднюю арифметическую из абсолютных значений отклонений вариант от средней величины, т.к. сумма отклонений значений признака от средней равно 0, то все отклонения берутся по модулю.
Простая
 Взвешенная
Взвешенная
Дисперсия – средний квадрат отклонений значений признака от их средней величины.
Простая:
 Взвешенная:
Взвешенная:
Среднее квадратическое отклонение . Оно определяется как квадратный корень из дисперсии и имеет ту же размерность, что и изучаемый признак.
Простая:
 Взвешенная:
Взвешенная: .
.
Относительные показатели
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ № 4 .
Расчёт структурных характеристик вариационного ряда распределения.
Студент должен:
знать:
- область применения и методику расчёта структурных средних величин;
уметь:
- исчислять структурные средние величины;
- формулировать вывод по полученным результатам.
Методические указания
В статистике исчисляются мода и медиана, которые относятся к структурным средним, так каких величина зависит от строения статистической совокупности.
Расчёт моды
Модой называется значение признака (варианта), чаще всеговстречающееся в изучаемой совокупности. В дискретном ряду распределения модой будет варианта с наибольшей частотой.
Например : Распределение проданной женской обуви по размерам характеризуется следующим образом:
|
Размер обуви |
||||||||
|
Количество проданных пар |
В этом ряду распределениямодой является 37 размер, т.е. Мо=37 размер .
Для интервального ряда распределения мода определяется по формуле:
где Х Mo - нижняя граница модального интервала;
h Mo - величина модального интервала;
f Mo – частота модального интервала;
f Mo -1и f Mo +1 – частота интервала соответственно
предшествующего модальному и следующего за ним.
Например : Распределение рабочих по стажу работы характеризуется следующими данными.
|
Стаж работы, лет |
до 2 |
8-10 |
10 и более |
|||
|
Число рабочих, чел. |
Определить моду интервального ряда распределения.
Мода интервального ряда составляет
Мода всегда бывает несколько неопределённой, т.к. она зависит от величины групп и точного положения границ групп. Мода широко применяется в коммерческой практике при изучении покупательского спроса, при регистрации цен и т.п.
Расчёт медианы
Медианой в статистике называется варианта, расположенная в середине упорядоченного ряда данных, и которая делит статистическую совокупность на две равные части так, что у одной половины значения меньше медианы, а у другой половины – больше её. Для определения медианы необходимо построить ранжированный ряд, т.е. ряд в порядке возрастания или убывания индивидуальных значений признака.
В дискретном упорядоченном ряду с нечётным числом членов медианой будет варианта, расположенная в центре ряда.
Например : Стаж пяти рабочих составил 2, 4, 7, 9 и 10 лет. В таком ряду медиана-7 лет, т.е. Ме=7 лет
Если дискретный упорядоченный ряд состоит из чётного числа членов, то медианой будет средняя арифметическая из двух смежных вариант, стоящих в центре ряда.
Например : Стаж работы шести рабочих составил 1, 3, 4, 5, 10 и 11лет. В этом ряду имеются две варианты, стоящие в центре ряда. Это варианты 4 и 5. Средняя арифметическая из этих значений и будет медианой ряда
![]()
Чтобы определить медиану для сгруппированных данных, необходимо считать накопленные частоты.
Например: По имеющимся данным определим медиану размера обуви
|
Размер обуви |
Количество проданных пар |
Сумма накопленных частот |
|
8+19=27 |
||
|
27+34=61 |
||
|
61+108=169 |
||
|
Итого |
Для определения медианы надо подсчитать сумму накопленных частот ряда. Наращивание итога продолжается до получения накопленной суммычастот, превышающей половину суммы частот ряда. В нашем примере сумма частот составила 300, её половина – 150. Накопленная сумма частот получилась равной 169. Варианта, соответствующая этой сумме, т.е. 37 и есть медиана ряда.
Если же сумма накопленных частот против одной из вариант равна точно половине суммы частот ряда, то медиана определяется как средняя арифметическая этой варианты и последующей.
Например : По имеющимся данным определим медиану заработной платы рабочих
|
Месячная заработная плата, тыс.р уб. |
Число рабочих, чел. |
Сумма накопленных частот |
|
14,0 |
||
|
14,2 |
2+6=8 |
|
|
16,0 |
8+12=20 |
|
|
16,8 |
||
|
18,0 |
||
|
Итого: |
Медиана будет равна: ![]()
Медиана интервального вариационного ряда распределения определяется по формуле:

ГдеХ Ме – нижняя граница медианного интервала;
h Me – величина медианного интервала;
∑ f - сумма частот ряда;
f Ме – частота медианного интервала;
Например: По имеющимся данным о распределении предприятий по численности промышленно – производственного персонала рассчитать медиану в интервальном вариационном ряду
|
Число предприятий |
Сумма накопленных частот |
|
|
100-200 |
||
|
200-300 |
1+3=4 |
|
|
300-400 |
4+7=11 |
|
|
400-500 |
11+30=41 |
|
|
500-600 |
||
|
600-700 |
||
|
700-800 |
||
|
Итого: |
Определим, прежде всего, медианный интервал. В данном примере сумма накопленных частот, превышающих половину суммы всех значений ряда, соответствует интервалу 400-500.Это и есть медианный интервал, т.е. интервал, в котором находится медиана ряда. Определим её значение

Если же сумма накопленных частот против одного из интервалов равна точно половине суммы частот ряда, то медиана определяется по формуле:

где n – число единиц в совокупности.
Например: По имеющимся данным о распределении предприятий по численности промышленно – производственного персонала рассчитать медиану в интервальном вариационном ряду
|
Группы предприятий по численности ППП, чел. |
Число предприятий |
Сумма накопленных частот |
|
100-200 |
||
|
200-300 |
1+3=4 |
|
|
300-400 |
4+6=10 |
|
|
400-500 |
10+30=40 |
|
|
500-600 |
40+20=60 |
|
|
600-700 |
||
|
700-800 |
||
|
Итого: |
 чел
чел
Моду и медиану в интервальном ряду можно определить графически:
моду в дискретных рядах - по полигону распределения, моду в интервальных рядах - по гистограмме распределения, а медиану - по кумуляте .
Мода интервального ряда распределения определяется по гистограмме распределения определяют следующим образом. Для этого выбирается самый высокий прямоугольник, который является в данном случае модальным. Затем правую вершину модального прямоугольника соединяем с правым верхним углом предыдущего прямоугольника. А левую вершину модального прямоугольника – с левым верхним углом последующего прямоугольника. Далее из точки их пересечения опускают перпендикуляр на ось абсцисс. Абсцисса точки пересечения этих прямых и будет модой распределения.

Медиана рассчитывается по кумуляте . Для её определения из точки на шкале накопленных частот (частостей ), соответствующей 50%, проводится прямая , параллельная оси абсцисс, до пересечения с кумулятой . Затем из точки пересечения указанной прямой с кумулятой опускается перпендикуляр на ось абсцисс. Абсцисса точки пересечения является медианой.

Кроме моды и медианы в вариантных рядах могут быть определены и другие структурные характеристики – квантили. Квантили предназначены для более глубокого изучения структуры ряда распределения.
Квантиль – это значение признака, занимающее определенное место в упорядоченной по данному признаку совокупности. Различают следующие виды квантилей:
- квартили – значения признака, делящие упорядоченную совокупность на четыре равные части;
- децили – значения признака, делящие упорядоченную совокупность на десять равных частей;
- перцентели - значения признака, делящие упорядоченную совокупность на сто равных частей.
Таким образом, для характеристики положения центра ряда распределения можно использовать 3 показателя: среднее значение признака , мода, медиана . При выборе вида и формы конкретного показателя центра распределения необходимо исходить из следующих рекомендаций:
- для устойчивых социально-экономических процессов в качестве показателя центра используют среднюю арифметическую. Такие процессы характеризуются симметричными распределениями, в которых ;
- для неустойчивых процессов положение центра распределения характеризуется с помощью Mo или Me . Для асимметричных процессов предпочтительной характеристикой центра распределения является медиана, поскольку занимает положение между средней арифметической и модой.
Cреднее арифметическое значение (далее по тексту — среднее), пожалуй, наиболее популярный статистический параметр. Этим понятием пользуются повсеместно — начиная от поговорки «средняя температура по больнице» и кончая серьезными научными трудами. Однако, как ни странно, среднее значение — коварное понятие, часто вводящее в заблуждение, вместо того чтобы придавать четкость изложению и вносить ясность.
Если говорить о научной работе, то статистический анализ данных применяется почти во всех прикладных науках, даже и в гуманитарных (например, психологии). Среднее значение вычисляется для признаков, измеряемых в так называемых непрерывных шкалах. Такими признаками являются, например, концентрации веществ в сыворотке крови, рост, вес, возраст. Среднее арифметическое можно легко вычислить, и этому учат еще в средней школе. Однако (в соответствии с положениями математической статистики) среднее значение является адекватной мерой центральной тенденции в выборке только в случае нормального (гауссова) распределения признака (рис. 1). Рис. 1. Нормальное (гауссово) распределение признака в выборке. Среднее (М) и медиана (Ме) совпадают
В случае же отклонения распределения от нормального закона среднее значение использовать некорректно, так как оно является слишком чувствительным параметром к так называемым «выбросам» — нехарактерным для изучаемой выборки, слишком большим или слишком малым значением (рис. 2). В этом случае для характеристики центральной тенденции в выборке должен применяться другой параметр — медиана. Медиана — это значение признака, справа и слева от которого находится равное число наблюдений (по 50%). Этот параметр (в отличие от среднего значения) устойчив к «выбросам». Заметим также, что медиана может использоваться и в случае нормального распределения — в этом случае медиана совпадает со средним значением.
 Рис. 2. Распределение признака в выборке, отличное от нормального. Среднее (м) и медиана (МЕ) не совпадают
Рис. 2. Распределение признака в выборке, отличное от нормального. Среднее (м) и медиана (МЕ) не совпадают
Для того, чтобы узнать, является ли распределение признака в выборке нормальным (гауссовым) или нет, т. е. для того, чтобы узнать, какой из параметров следует применять (среднее значение или медиану), существуют специальные статистические тесты.
Приведем пример. Скорость оседания эритроцитов в группе пациентов, недавно перенесших пневмонию, — 3, 5, 5, 7, 11, 12, 16, 16, 21, 42, 58. Среднее значение для этой выборки равно 17,8, медиана — 12. Распределение (по тесту Шапиро—Уилка) нормальным не является (рис. 3), поэтому использовать надо медиану.  Рис. 3. Пример
Рис. 3. Пример
Как ни странно, но в некоторых областях экономики сторонний наблюдатель не может заметить хоть какого-то следа корректного применения математической статистики. Так, нам постоянно говорят о средней зарплате (например, в НИИ), и эти числа обычно удивляют не только рядовых сотрудников, но и руководителей подразделений (ныне называемых «менеджерами среднего звена»). Мы удивляемся, что средняя зарплата в Москве — 40 тыс. руб., но, конечно, понимаем, что нас «усреднили» с олигархами. Вот пример из жизни научных работников: зарплаты сотрудников лаборатории (тыс. руб.) — 3, 5, 5, 7, 11, 12, 16, 16, 21, 42, 58. Среднее значение — 17,8, медиана — 12. Согласитесь, что это разные числа!
Конечно, нельзя исключить, что замалчивание свойств среднего — лукавство, так как руководству всегда выгоднее представить ситуацию с зарплатой сотрудников лучше, чем она есть на самом деле.
Не пора ли научному сообществу призвать наших руководителей прекратить некорректное использование математической статистики?
Ольга Реброва,
докт. мед. наук, вице-президент
МОО «Общество специалистов доказательной медицины»