Как построить линию регрессии в эксель. Корреляционно-регрессионный анализ в Excel: инструкция выполнения. §4.3. Основные виды нелинейной регрессии
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:


После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.


В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:



Теперь стали видны и данные регрессионного анализа.
Понятие регрессии . Зависимость между переменными величинами x и y может быть описана разными способами. В частности, любую форму связи можно выразить уравнением общего вида , гдеy рассматривается в качестве зависимой переменной, или функции от другой – независимой переменной величины x, называемой аргументом . Соответствие между аргументом и функцией может быть задано таблицей, формулой, графиком и т.д. Изменение функции в зависимости от изменения одного или нескольких аргументов называется регрессией . Все средства, применяемые для описания корреляционных связей, составляет содержание регрессионного анализа .
Для выражения регрессии служат корреляционные уравнения, или уравнения регрессии, эмпирические и теоретически вычисленные ряды регрессии, их графики, называемые линиями регрессии, а также коэффициенты линейной и нелинейной регрессии.
Показатели регрессии выражают корреляционную связь двусторонне, учитывая изменение усредненных значений признакаY при изменении значений x i признака X , и, наоборот, показывают изменение средних значений признакаX по измененным значениям y i признака Y . Исключение составляют временные ряды, или ряды динамики, показывающие изменение признаков во времени. Регрессия таких рядов является односторонней.
Различных форм и видов корреляционных связей много. Задача сводится к тому, чтобы в каждом конкретном случае выявить форму связи и выразить ее соответствующим корреляционным уравнением, что позволяет предвидеть возможные изменения одного признака Y на основании известных изменений другого X , связанного с первым корреляционно.
12.1 Линейная регрессия
Уравнение регрессии. Результаты наблюдений, проведенных над тем или иным биологическим объектом по корреляционно связанным признакам x и y , можно изобразить точками на плоскости, построив систему прямоугольных координат. В результате получается некая диаграмма рассеяния, позволяющая судить о форме и тесноте связи между варьирующими признаками. Довольно часто эта связь выглядит в виде прямой или может быть аппроксимирована прямой линией.
Линейная зависимость между переменными x и y описывается уравнением общего вида , гдеa, b, c, d, … – параметры уравнения, определяющие соотношения между аргументами x 1 , x 2 , x 3 , …, x m и функций .
В практике учитывают не все возможные, а лишь некоторые аргументы, в простейшем случае – всего один:
В уравнении линейной регрессии (1) a – свободный член, а параметр b определяет наклон линии регрессии по отношению к осям прямоугольных координат. В аналитической геометрии этот параметр называют угловым коэффициентом , а в биометрии – коэффициентом регрессии . Наглядное представление об этом параметре и о положении линий регрессии Y по X и X по Y в системе прямоугольных координат дает рис.1.

Рис. 1 Линии регрессии Y по X и X поY в системе
прямоугольных координат
Линии регрессии, как показано на рис.1, пересекаются в точке О (,), соответствующей средним арифметическим значениям корреляционно связанных друг с другом признаковY и X . При построении графиков регрессии по оси абсцисс откладывают значения независимой переменной X, а по оси ординат – значения зависимой переменной, или функции Y. Линия АВ, проходящая через точку О (,) соответствует полной (функциональной) зависимости между переменными величинамиY и X , когда коэффициент корреляции . Чем сильнее связь междуY и X , тем ближе линии регрессии к АВ, и, наоборот, чем слабее связь между этими величинами, тем более удаленными оказываются линии регрессии от АВ. При отсутствии связи между признаками линии регрессии оказываются под прямым углом по отношению друг к другу и .
Поскольку показатели регрессии выражают корреляционную связь двусторонне, уравнение регрессии (1) следует записывать так:
По первой формуле определяют усредненные значения при изменении признакаX на единицу меры, по второй – усредненные значения при изменении на единицу меры признакаY .
Коэффициент регрессии. Коэффициент регрессии показывает, насколько в среднем величина одного признака y изменяется при изменении на единицу меры другого, корреляционно связанного с Y признака X . Этот показатель определяют по формуле
Здесь значения s умножают на размеры классовых интервалов λ , если их находили по вариационным рядам или корреляционным таблицам.
Коэффициент регрессии можно вычислить минуя расчет средних квадратичных отклонений s y и s x по формуле
Если же коэффициент корреляции неизвестен, коэффициент регрессии определяют следующим образом:
Связь между коэффициентами регрессии и корреляции. Сравнивая формулы (11.1) (тема 11) и (12.5), видим: в их числителе одна и та же величина , что указывает на наличие связи между этими показателями. Эта связь выражается равенством
Таким образом, коэффициент корреляции равен средней геометрической из коэффициентов b yx и b xy . Формула (6) позволяет, во-первых, по известным значениям коэффициентов регрессии b yx и b xy определять коэффициент регрессии R xy , а во-вторых, проверять правильность расчета этого показателя корреляционной связи R xy между варьирующими признаками X и Y .
Как и коэффициент корреляции, коэффициент регрессии характеризует только линейную связь и сопровождается знаком плюс при положительной и знаком минус при отрицательной связи.
Определение параметров линейной регрессии. Известно, что сумма квадратов отклонений вариант x i от средней есть величина наименьшая, т.е.. Эта теорема составляет основу метода наименьших квадратов. В отношении линейной регрессии [см. формулу (1)] требованию этой теоремы удовлетворяет некоторая система уравнений, называемыхнормальными :
Совместное решение этих уравнений относительно параметров a и b приводит к следующим результатам:
![]() ;
;
![]() ;
;
![]() ,
откуда
и.
,
откуда
и.
Учитывая двусторонний характер связи между переменными Y и X , формулу для определения параметра а следует выразить так:
![]() и
. (7)
и
. (7)
Параметр b , или коэффициент регрессии, определяют по следующим формулам:
Построение эмпирических рядов регрессии. При наличии большого числа наблюдений регрессионный анализ начинается с построения эмпирических рядов регрессии. Эмпирический ряд регрессии образуется путем вычисления по значениям одного варьирующего признака X средних значений другого, связанного корреляционно сX признака Y . Иными словами, построение эмпирических рядов регрессии сводится к нахождению групповых средних ииз соответствующих значений признаковY и X.
Эмпирический ряд регрессии – это двойной ряд чисел, которые можно изобразить точками на плоскости, а затем, соединив эти точки отрезками прямой, получить эмпирическую линию регрессии. Эмпирические ряды регрессии, особенно их графики, называемые линиями регрессии , дают наглядное представление о форме и тесноте корреляционной зависимости между варьирующими признаками.
Выравнивание эмпирических рядов регрессии. Графики эмпирических рядов регрессии оказываются, как правило, не плавно идущими, а ломаными линиями. Это объясняется тем, что наряду с главными причинами, определяющими общую закономерность в изменчивости коррелируемых признаков, на их величине сказывается влияние многочисленных второстепенных причин, вызывающих случайные колебания узловых точек регрессии. Чтобы выявить основную тенденцию (тренд) сопряженной вариации коррелируемых признаков, нужно заменить ломанные линии на гладкие, плавно идущие линии регрессии. Процесс замены ломанных линий на плавно идущие называют выравниванием эмпирических рядов и линий регрессий .
Графический способ выравнивания. Это наиболее простой способ, не требующий вычислительной работы. Его сущность сводится к следующему. Эмпирический ряд регрессии изображают в виде графика в системе прямоугольных координат. Затем визуально намечаются средние точки регрессии, по которым с помощью линейки или лекала проводят сплошную линию. Недостаток этого способа очевиден: он не исключает влияние индивидуальных свойств исследователя на результаты выравнивания эмпирических линий регрессии. Поэтому в тех случаях, когда необходима более высокая точность при замене ломанных линий регрессии на плавно идущие, используют другие способы выравнивания эмпирических рядов.
Способ скользящей средней. Суть этого способа сводится к последовательному вычислению средних арифметических из двух или трех соседних членов эмпирического ряда. Этот способ особенно удобен в тех случаях, когда эмпирический ряд представлен большим числом членов, так что потеря двух из них – крайних, что неизбежно при этом способе выравнивания, заметно не отразится на его структуре.
Метод наименьших квадратов. Этот способ предложен в начале XIX столетия А.М. Лежандром и независимо от него К. Гауссом. Он позволяет наиболее точно выравнивать эмпирические ряды. Этот метод, как было показано выше, основан на предположении, что сумма квадратов отклонений вариант x i от их средней есть величина минимальная, т.е.. Отсюда и название метода, который применяется не только в экологии, но и в технике. Метод наименьших квадратов объективен и универсален, его применяют в самых различных случаях при отыскании эмпирических уравнений рядов регрессии и определении их параметров.
Требование метода наименьших квадратов заключается в том, что теоретические точки линии регрессии должны быть получены таким образом, чтобы сумма квадратов отклонений от этих точек для эмпирических наблюденийy i была минимальной, т.е.
Вычисляя в соответствии с принципами математического анализа минимум этого выражения и определенным образом преобразуя его, можно получить систему так называемых нормальных уравнений , в которых неизвестными величинами оказываются искомые параметры уравнения регрессии, а известные коэффициенты определяются эмпирическими величинами признаков, обычно суммами их значений и их перекрестных произведений.
Множественная линейная регрессия. Зависимость между несколькими переменными величинами принято выражать уравнением множественной регрессии, которая может быть линейной и нелинейной . В простейшем виде множественная регрессия выражается уравнением с двумя независимыми переменными величинами (x , z ):
где a – свободный член уравнения; b и c – параметры уравнения. Для нахождения параметров уравнения (10) (по способу наименьших квадратов) применяют следующую систему нормальных уравнений:
Ряды динамики. Выравнивание рядов. Изменение признаков во времени образует так называемые временные ряды или ряды динамики . Характерной особенностью таких рядов является то, что в качестве независимой переменной X здесь всегда выступает фактор времени, а зависимой Y – изменяющийся признак. В зависимости от рядов регрессии зависимость между переменными X и Y носит односторонний характер, так как фактор времени не зависит от изменчивости признаков. Несмотря на указанные особенности, ряды динамики можно уподобить рядам регрессии и обрабатывать их одними и теми же методами.
Как и ряды регрессии, эмпирические ряды динамики несут на себе влияние не только основных, но и многочисленных второстепенных (случайных) факторов, затушевывающих ту главную тенденцию в изменчивости признаков, которая на языке статистики называют трендом .
Анализ рядов динамики начинается с выявления формы тренда. Для этого временной ряд изображают в виде линейного графика в системе прямоугольных координат. При этом по оси абсцисс откладывают временные точки (годы, месяцы и другие единицы времени), а по оси ординат – значения зависимой переменной Y. При наличии линейной зависимости между переменными X и Y (линейного тренда) для выравнивания рядов динамики способом наименьших квадратов наиболее подходящим является уравнение регрессии в виде отклонений членов ряда зависимой переменной Y от средней арифметической ряда независимой переменнойX:
Здесь – параметр линейной регрессии.
Числовые характеристики рядов динамики. К числу основных обобщающих числовых характеристик рядов динамики относят среднюю геометрическую и близкую к ней среднюю арифметическуювеличины. Они характеризуют среднюю скорость, с какой изменяется величина зависимой переменной за определенные периоды времени:
Оценкой изменчивости членов ряда динамики служит среднее квадратическое отклонение . При выборе уравнений регрессии для описания рядов динамики учитывают форму тренда, которая может быть линейной (или приведена к линейной) и нелинейной. О правильности выбора уравнения регрессии обычно судят по сходству эмпирически наблюденных и вычисленных значений зависимой переменной. Более точным в решении этой задачи является метод дисперсионного анализа регрессии (тема 12 п.4).
Корреляция рядов динамики. Нередко приходится сопоставлять динамику параллельно идущих временных рядов, связанных друг с другом некоторыми общими условиями, например выяснить связь между производством сельскохозяйственной продукции и ростом поголовья скота за определенный промежуток времени. В таких случаях характеристикой связи между переменными X и Y служит коэффициент корреляции R xy (при наличии линейного тренда).
Известно, что тренд рядов динамики, как правило, затушевывается колебаниями членов ряда зависимой переменной Y. Отсюда возникает задача двоякого рода: измерение зависимости между сопоставляемыми рядами, не исключая тренд, и измерение зависимости между соседними членами одного и того же ряда, исключая тренд. В первом случае показателем тесноты связи между сопоставляемыми рядами динамики служит коэффициент корреляции (если связь линейна), во втором – коэффициент автокорреляции . Эти показатели имеют разные значения, хотя и вычисляются по одним и тем же формулам (см. тему 11).
Нетрудно заметить, что на значении коэффициента автокорреляции сказывается изменчивость членов ряда зависимой переменной: чем меньше члены ряда отклоняются от тренда, тем выше коэффициент автокорреляции, и наоборот.
Линия регрессии является графическим отражением взаимосвязи между явлениями. Очень наглядно можно построить линию регрессии в программе Excel.
Для этого необходимо:
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем строить линию регрессии, или взаимосвязи, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах

3.Затем необходимо выделить оба столбика (без названия столбика), нажать вкладку вставка , выбрать точечная , а из предложенных макетов выбрать самый первый точечная с маркерами .

4.Итак у нас получилась заготовка для линии регрессии — так называемая — диаграмма рассеяния . Для перехода к линии регрессии нужно щёлкнуть на получившийся рисунок, нажать вкладку конструктор, найти на панели макеты диаграмм и выбрать Ма кет9 , на нем ещё написано f(x)

5.Итак, у нас получилась линия регрессии. На графике также указано её уравнение и квадрат коэффициента корреляции

6.Осталось добавить название графика, название осей. Также по желанию можно убрать легенду, уменьшить количество горизонтальных линий сетки (вкладка макет , затем сетка ). Основные изменения и настройки производятся во вкладке Макет

Линия регрессии построена в MS Excel. Теперь её можно добавить в текст работы.
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».
- Переходим в раздел «Параметры».
- Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
- В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
- Открывается окно доступных надстроек Эксель. Ставим галочку около пункта «Пакет анализа». Жмем на кнопку «OK».

Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.


Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае - это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ - ожидаемое значение у при заданном значении х,
x - независимая переменная,
a - отрезок на оси y для прямой линии,
b - наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у - это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ - это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг - определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по методу наименьших квадратов.
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.
Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.
Чтобы продемонстрировать работу надстройки, воспользуемся данными с предыдущей статьи, где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.
Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:
Щелкните ОК. На рисунке ниже показаны полученные результаты:
Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в предыдущей статье.
Регрессионный анализ - это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику Фрэнсисом Гальтоном в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а0 + а1×1 +…+аkxk, где хi - влияющие переменные, ai - коэффициенты регрессии, a k - число факторов.
Для данной задачи Y - это показатель уволившихся сотрудников, а влияющий фактор - зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
Линейная регрессия в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата tкр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:
- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.
Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO – 0,031*VK +0,405*VD +0,691*VZP – 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 – 0,031*x3 +0,405*x4 +0,691*x5 – 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
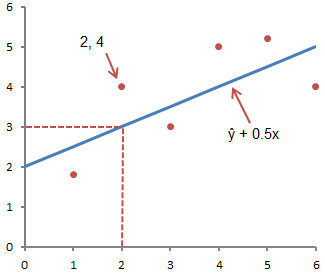
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг - определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по .
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.

Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.

Чтобы продемонстрировать работу надстройки, воспользуемся данными , где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.

Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:

Щелкните ОК. На рисунке ниже показаны полученные результаты:
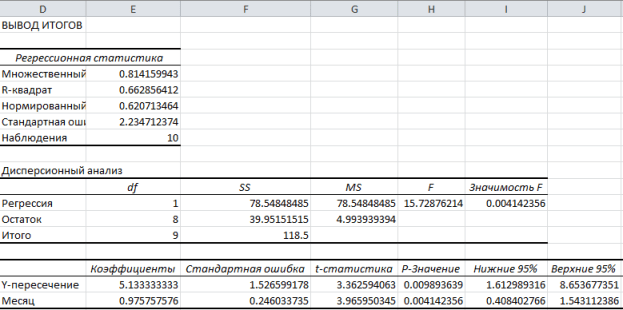
Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в .