Нечетким логическим выводом называется замена зависимости. Нечеткие выводы. Формирование базы правил нечеткого вывода
В задачах математического моделирования часто возникает задача описания переменных, представляющих качественные значения показателей, слабо формализуемых в дискретный набор значений Коротеев, М.В. Аналитическая дефаззификация нечётких чисел / Коротеев М.В. // Известия ВолгГТУ. Серия «Актуальные проблемы управления, вычислительной техники и информатики в технических системах». Вып. 14: межвуз. сб. науч. ст. / ВолгГТУ. - Волгоград, 2012. - № 10 (97). - C. 32-35.. Примером таких показателей может служить качество товара, эффективность работы учреждения, квалификация сотрудников и многие другие. В то же время, традиционно уровни таких показателей оцениваются качественно, с использованием экспертных оценок, формулируемых с помощью лингвистических понятий «низкий», «высокий», «очень высокий». Оперирование лингвистическими понятиями представляет определенную сложность, преодоление которой требует привлечения определенного математического аппарата.
Нами в наших исследованиях был выбран аппарат нечеткой логики, так как он предоставляет гибкую возможность вычислений в лингвистических термах, оперирование неопределенностью в условиях недостатка информации. Лингвистические переменные Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. М.: Мир, 1976. 166c. могут формализовать неточные, многозначные и неопределенные понятия. Это свойство весьма полезно для использования в экспертных системах, так как предоставляет методологию, позволяющую экспертам выражать свои знания в привычной для них лингвистической форме и оперировать ими как строгими математическими объектами. Далее, адаптируем алгоритм нечеткого вывода для использования в Байесовских сетях.
Центральным понятием нечеткого вывода является лингвистическая переменная - переменная, имеющая определенный набор лингвистических значений (термов), построенная на определенной области определения (обычно, действительном интервале) Murphy, Kevin (2002). Dynamic Bayesian Networks: Representation, Inference and Learning. UC Berkeley, Computer Science Division. Jensen Finn V. Bayesian Networks and Decision Graphs. -- Springer, 2001.. Для примера рассмотрим лингвистическую переменную «КАЧЕСТВО». Мы можем определить некий интегральный показатель качества, оценивающий качество в некоей шкале. Путем нормализации, практически любую шкалу мы можем привести в отрезок . В дальнейшем, будем использовать именно этот отрезок как иллюстрацию носителя в силу его универсальности и общеупотребимости.
Каждый уровень качества может быть охарактеризован как низкий, средний или высокий, но в разной степени. Этот набор является набором значений лингвистической переменной. Таким образом, каждому значению лингвистической переменной соответствует функция принадлежности где x - элемент области определения, определенная на области определения данной переменной. Эта функция показывает, насколько применимо в данной точке области определения данное значение. Функция принадлежности обычно принимает значения из интервала , где значение 0 показывает, что данное значение абсолютно не применимо в данной точке, а значение 1 говорит об абсолютной применимости данного значения. Набор данных функций называется нечетким классификатором Коротеев, М.В. Проектирование программной реализации носителей нечётких множеств / Коротеев М.В. // Объектные системы - 2011 (Зимняя сессия) : матер. V междунар. науч.-практ. конф. (Ростов-на-Дону, 10-12 дек. 2011 г.) / Шахтинский ин-т (филиал) ГОУ ВПО ЮРГТУ (НПИ) [и др.]. - Ростов н/Д, 2011. - C. 44-49.. В случае обычной четкой переменной, каждая точка области определения может принадлежать одному и только одному значению. В нечеткой логике, каждая точка принадлежит всем значениям, но в разной степени.
Простой нечеткий классификатор
На рисунке изображен нечеткий классификатор с тремя термами (слева направо: «низкий уровень», «средний уровень», «высокий уровень»). Носителем данной лингвистической переменной является отрезок (горизонтальная ось). Область значений функции принадлежности - также отрезок (вертикальная ось). Можно увидеть, что точка, например, 0,3 принадлежит терму «низкий уровень» со степенью принадлежности 0,5; «средний уровень» - с принадлежностью также 0,5, «высокий уровень» - с принадлежностью 0. Нестрого можно сказать, что данная точка не принадлежит терму «высокий уровень» вообще.
Для каждой точки области определения, сумма ее принадлежностей ко всем термам переменной равна 1
Для каждой точки области определения, существует не более двух и не менее одного терма, принадлежность к которым данной точки положительна.
Для каждого терма лингвистической переменной существует по меньшей мере одна точка, принадлежность которой к данному терму равна 1.

Нечеткий классификатор, не являющийся нечетким разбиением.
Рассмотрим алгоритм нечеткого логического вывода на примере алгоритма Мамдани Коротеев, М.В. Разработка арифметики нечётких чисел в общей форме / Коротеев М.В. // Известия ВолгГТУ. Серия «Актуальные проблемы управления, вычислительной техники и информатики в технических системах». Вып. 13: межвуз. сб. науч. ст. / ВолгГТУ. - Волгоград, 2012. - № 4 (91). - C. 122-127. . Допустим, существует две лингвистические переменные А и В, каждая из которых определена на интервале и принимает значения из множества {«low», «middle», «high»}, характеризующие качественный уровень показателя. Значения переменной В нечетко зависят от значений переменной А по следующему набору правил логического вывода (аналогично правилам четкого логического вывода):
Система правил нечеткого логического вывода
Исходя из этих данных, каждому правилу вывода присваивается вес, показывающий, в какой степени данное правило применимо при данном наблюдении:
Взвешенная система правил нечеткого логического вывода
В данном простом примере используем значения функций принадлежности как веса правил. Исходя из полученных результатов, переменная В примет значение, равное значению выражения |0.7*”high” + 0.3*”middle”|. Рассматривая каждый терм как НПМ, мы можем вычислить значение данного выражения. и оно гарантированно будет являться элементом области определения лингвистической переменной В. Кроме численного значения, в качестве результата процесса вывода может рассматриваться и нечетко-множественное представление в виде НПМ С = 0.7*”high” + 0.3*”middle”. В общем случае, для вычисления результата нечеткого логического вывода, достаточно вычислить веса всех термов целевой переменной.
Рассмотрим пример более сложного нечеткого вывода. Имеем три аналогичные переменные, А, В и С, где значение С зависит от значений А и В по следующему набору правил:
Система правил вывода для двух условных переменных
Как видно из таблицы, система правил нечеткого вывода использует аналогичный механизм, когда перечисляются все возможные назначения условных переменных в разделе ЕСЛИ, и каждому назначению из них. поставлено в соответствие назначение подусловной переменной в разделе ТО.
Вычислим значения весов правил как произведения соответствующих принадлежностей: В качестве оператора комбинации при вычислении весов правил в нечетком выводе применяются различные треугольные нормы, но мы воспользуемся самой простой функцией.
Взвешенная система правил вывода двух условных переменных
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) являются обобщениями классической теории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких и приближенных рассуждений при описании человеком процессов, систем, объектов.
Прежде чем нечеткий подход к моделированию сложных систем получил признание во всем мире, прошло не одно десятилетие с момента зарождения теории нечетких множеств. И на этом пути развития нечетких систем принято выделять три периода.
Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э. Мамдани, Беллман). Во втором периоде (70–80-е годы) появляются первые практические результаты в области нечеткого управления сложными техническими системами (парогенератор с нечетким управлением). Одновременно стало уделяться внимание вопросам построения экспертных систем, построенных на нечеткой логике, разработке нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других.
Триумфальное шествие нечеткой логики по миру началось после доказательства в конце 80-х Бартоломеем Коско знаменитой теоремы FAT (Fuzzy Approximation Theorem). В бизнесе и финансах нечеткая логика получила признание после того как в 1988 году экспертная система на основе нечетких правил для прогнозирования финансовых индикаторов единственная предсказала биржевой крах. И количество успешных фаззи-применений в настоящее время исчисляется тысячами.
Математический аппарат
Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF c (x) – степень принадлежности к нечеткому множеству C, представляющей собой обобщение понятия характеристической функции обычного множества. Тогда нечетким множеством С называется множество упорядоченных пар вида C={MF c (x)/x}, MF c (x) . Значение MF c (x)=0 означает отсутствие принадлежности к множеству, 1 – полную принадлежность.
Проиллюстрируем это на простом примере. Формализуем неточное определение "горячий чай". В качестве x (область рассуждений) будет выступать шкала температуры в градусах Цельсия. Очевидно, что она будет изменяется от 0 до 100 градусов. Нечеткое множество для понятия "горячий чай" может выглядеть следующим образом:
C={0/0; 0/10; 0/20; 0,15/30; 0,30/40; 0,60/50; 0,80/60; 0,90/70; 1/80; 1/90; 1/100}.
Так, чай с температурой 60 С принадлежит к множеству "Горячий" со степенью принадлежности 0,80. Для одного человека чай при температуре 60 С может оказаться горячим, для другого – не слишком горячим. Именно в этом и проявляется нечеткость задания соответствующего множества.
Для нечетких множеств, как и для обычных, определены основные логические операции. Самыми основными, необходимыми для расчетов, являются пересечение и объединение.
Пересечение двух нечетких множеств (нечеткое "И"): A B: MF AB (x)=min(MF A (x), MF B (x)).
Объединение двух нечетких множеств (нечеткое "ИЛИ"): A B: MF AB (x)=max(MF A (x), MF B (x)).
В теории нечетких множеств разработан общий подход к выполнению операторов пересечения, объединения и дополнения, реализованный в так называемых треугольных нормах и конормах. Приведенные выше реализации операций пересечения и объединения – наиболее распространенные случаи t-нормы и t-конормы.
Для описания нечетких множеств вводятся понятия нечеткой и лингвистической переменных.
Нечеткая переменная описывается набором (N,X,A), где N – это название переменной, X – универсальное множество (область рассуждений), A – нечеткое множество на X.
Значениями лингвистической переменной могут быть нечеткие переменные, т.е. лингвистическая переменная находится на более высоком уровне, чем нечеткая переменная. Каждая лингвистическая переменная состоит из:
- названия;
- множества своих значений, которое также называется базовым терм-множеством T. Элементы базового терм-множества представляют собой названия нечетких переменных;
- универсального множества X;
- синтаксического правила G, по которому генерируются новые термы с применением слов естественного или формального языка;
- семантического правила P, которое каждому значению лингвистической переменной ставит в соответствие нечеткое подмножество множества X.
Рассмотрим такое нечеткое понятие как "Цена акции". Это и есть название лингвистической переменной. Сформируем для нее базовое терм-множество, которое будет состоять из трех нечетких переменных: "Низкая", "Умеренная", "Высокая" и зададим область рассуждений в виде X= (единиц). Последнее, что осталось сделать – построить функции принадлежности для каждого лингвистического терма из базового терм-множества T.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:
$$MF\,(x) = \,\begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac{x\,-\,b}{c\,-\,b},\,b\leq \,x\leq \,c &\ \\ 0, \;x\,\not \in\,(a;\,c)\ \end{cases}$$
При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):
$$MF\,(x)\,=\, \begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac{x\,-\,c}{d\,-\,c},\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end{cases}$$
При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
Функция принадлежности гауссова типа описывается формулой
$$MF\,(x) = \exp\biggl[ -\,{\Bigl(\frac{x\,-\,c}{\sigma}\Bigr)}^2\biggr]$$
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.

Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке 3 приведен пример описанной выше лингвистической переменной "Цена акции", на рисунке 4 – формализация неточного понятия "Возраст человека". Так, для человека 48 лет степень принадлежности к множеству "Молодой" равна 0, "Средний" – 0,47, "Выше среднего" – 0,20.
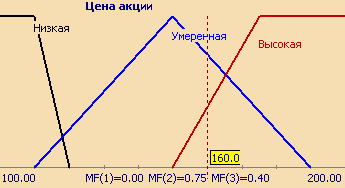
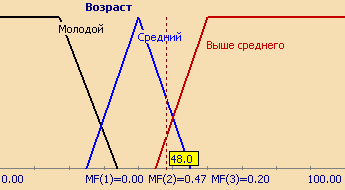
Количество термов в лингвистической переменной редко превышает 7.
Нечеткий логический вывод
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
- Существует хотя бы одно правило для каждого лингвистического терма выходной переменной.
- Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида:
R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1
…
R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i
…
R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m ,
где x k , k=1..n – входные переменные; y – выходная переменная; A ik – заданные нечеткие множества с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).
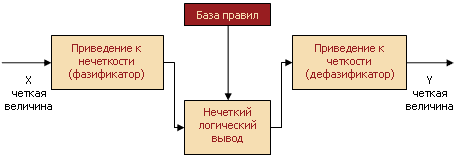
Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
- Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
$$alfa_i\,=\,\min_i \,(A_{ik}\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
где MF(y) – функция принадлежности итогового нечеткого множества.
Дефазификация, или приведение к четкости. Существует несколько методов дефазификации. Например, метод среднего центра, или центроидный метод:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
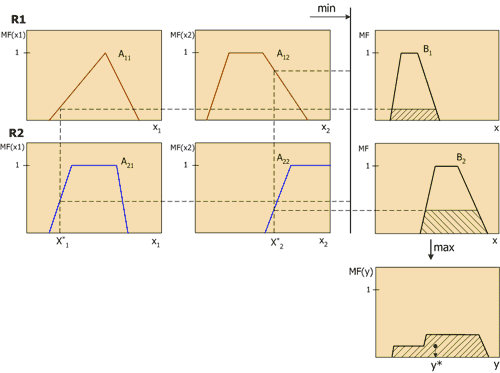
Геометрический смысл такого значения – центр тяжести для кривой MF(y). Рисунок 6 графически показывает процесс нечеткого вывода по Мамдани для двух входных переменных и двух нечетких правил R1 и R2.
Интеграция с интеллектуальными парадигмами
Гибридизация методов интеллектуальной обработки информации – девиз, под которым прошли 90-е годы у западных и американских исследователей. В результате объединения нескольких технологий искусственного интеллекта появился специальный термин – "мягкие вычисления" (soft computing), который ввел Л. Заде в 1994 году. В настоящее время мягкие вычисления объединяют такие области как: нечеткая логика, искусственные нейронные сети, вероятностные рассуждения и эволюционные алгоритмы. Они дополняют друг друга и используются в различных комбинациях для создания гибридных интеллектуальных систем.
Влияние нечеткой логики оказалось, пожалуй, самым обширным. Подобно тому, как нечеткие множества расширили рамки классической математическую теорию множеств, нечеткая логика "вторглась" практически в большинство методов Data Mining, наделив их новой функциональностью. Ниже приводятся наиболее интересные примеры таких объединений.
Нечеткие нейронные сети
Нечеткие нейронные сети (fuzzy-neural networks) осуществляют выводы на основе аппарата нечеткой логики, однако параметры функций принадлежности настраиваются с использованием алгоритмов обучения НС. Поэтому для подбора параметров таких сетей применим метод обратного распространения ошибки, изначально предложенный для обучения многослойного персептрона. Для этого модуль нечеткого управления представляется в форме многослойной сети. Нечеткая нейронная сеть как правило состоит из четырех слоев: слоя фазификации входных переменных, слоя агрегирования значений активации условия, слоя агрегирования нечетких правил и выходного слоя.
Наибольшее распространение в настоящее время получили архитектуры нечеткой НС вида ANFIS и TSK. Доказано, что такие сети являются универсальными аппроксиматорами.
Быстрые алгоритмы обучения и интерпретируемость накопленных знаний – эти факторы сделали сегодня нечеткие нейронные сети одним из самых перспективных и эффективных инструментов мягких вычислений.
Адаптивные нечеткие системы
Классические нечеткие системы обладают тем недостатком, что для формулирования правил и функций принадлежности необходимо привлекать экспертов той или иной предметной области, что не всегда удается обеспечить. Адаптивные нечеткие системы (adaptive fuzzy systems) решают эту проблему. В таких системах подбор параметров нечеткой системы производится в процессе обучения на экспериментальных данных. Алгоритмы обучения адаптивных нечетких систем относительно трудоемки и сложны по сравнению с алгоритмами обучения нейронных сетей, и, как правило, состоят из двух стадий: 1. Генерация лингвистических правил; 2. Корректировка функций принадлежности. Первая задача относится к задаче переборного типа, вторая – к оптимизации в непрерывных пространствах. При этом возникает определенное противоречие: для генерации нечетких правил необходимы функции принадлежности, а для проведения нечеткого вывода – правила. Кроме того, при автоматической генерации нечетких правил необходимо обеспечить их полноту и непротиворечивость.
Значительная часть методов обучения нечетких систем использует генетические алгоритмы. В англоязычной литературе этому соответствует специальный термин – Genetic Fuzzy Systems.
Значительный вклад в развитие теории и практики нечетких систем с эволюционной адаптацией внесла группа испанских исследователей во главе с Ф. Херрера (F. Herrera).
Нечеткие запросы
Нечеткие запросы к базам данных (fuzzy queries) – перспективное направление в современных системах обработки информации. Данный инструмент дает возможность формулировать запросы на естественном языке, например: "Вывести список недорогих предложений о съеме жилья близко к центру города", что невозможно при использовании стандартного механизма запросов. Для этой цели разработана нечеткая реляционная алгебра и специальные расширения языков SQL для нечетких запросов. Большая часть исследований в этой области принадлежит западноевропейским ученым Д. Дюбуа и Г. Праде.
Нечеткие ассоциативные правила
Нечеткие ассоциативные правила (fuzzy associative rules) – инструмент для извлечения из баз данных закономерностей, которые формулируются в виде лингвистических высказываний. Здесь введены специальные понятия нечеткой транзакции, поддержки и достоверности нечеткого ассоциативного правила.
Нечеткие когнитивные карты
Нечеткие когнитивные карты (fuzzy cognitive maps) были предложены Б. Коско в 1986 г. и используются для моделирования причинных взаимосвязей, выявленных между концептами некоторой области. В отличие от простых когнитивных карт, нечеткие когнитивные карты представляют собой нечеткий ориентированный граф, узлы которого являются нечеткими множествами. Направленные ребра графа не только отражают причинно-следственные связи между концептами, но и определяют степень влияния (вес) связываемых концептов. Активное использование нечетких когнитивных карт в качестве средства моделирования систем обусловлено возможностью наглядного представления анализируемой системы и легкостью интерпретации причинно-следственных связей между концептами. Основные проблемы связаны с процессом построения когнитивной карты, который не поддается формализации. Кроме того, необходимо доказать, что построенная когнитивная карта адекватна реальной моделируемой системе. Для решения данных проблем разработаны алгоритмы автоматического построения когнитивных карт на основе выборки данных.
Нечеткая кластеризация
Нечеткие методы кластеризации, в отличие от четких методов (например, нейронные сети Кохонена), позволяют одному и тому же объекту принадлежать одновременно нескольким кластерам, но с различной степенью. Нечеткая кластеризация во многих ситуациях более "естественна", чем четкая, например, для объектов, расположенных на границе кластеров. Наиболее распространены: алгоритм нечеткой самоорганизации c-means и его обобщение в виде алгоритма Густафсона-Кесселя.
Литература
- Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. – М.: Мир, 1976.
- Круглов В.В., Дли М.И. Интеллектуальные информационные системы: компьютерная поддержка систем нечеткой логики и нечеткого вывода. – М.: Физматлит, 2002.
- Леоленков А.В. Нечеткое моделирование в среде MATLAB и fuzzyTECH. – СПб., 2003.
- Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. – М., 2004.
- Масалович А. Нечеткая логика в бизнесе и финансах. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Fuzzy systems as universal approximators // IEEE Transactions on Computers, vol. 43, No. 11, November 1994. – P. 1329-1333.
- Cordon O., Herrera F., A General study on genetic fuzzy systems // Genetic Algorithms in engineering and computer science, 1995. – P. 33-57.
2.1 Основные понятия нечеткой логики
Как было упомянуто в предыдущих главах, классическая логика оперирует только двумя понятиями: «истина» и «ложь», и исключая любые промежуточные значения. Аналогично этому булева логика не признает ничего кроме единиц и нулей.
Нечеткая же логика основана на использовании оборотов естественного языка. Человек сам определяет необходимое число терминов и каждому из них ставит в соответствие некоторое значение описываемой физической величины. Для этого значения степень принадлежности физической величины к терму (слову естественного языка, характеризующего переменную) будет равна единице, а для всех остальных значений ‒ в зависимости от выбранной функции принадлежности.
При помощи нечетких множеств можно формально определить неточные и многозначные понятия, такие как «высокая температура», «молодой человек», «средний рост» либо «большой город». Перед формулированием определения нечеткого множества необходимо задать так называемую область рассуждений (universe of discourse). В случае неоднозначного понятия «много денег» большой будет признаваться одна сумма, если мы ограничимся диапазоном и совсем другая–в диапазоне .
Лингвистические переменные:
Лингвистической переменной является переменная, для задания которой используются лингвистические значения, выражающие качественные оценки, или нечеткие числа. Примером лингвистической переменной может быть скорость или температура, примером лингвистического значения - характеристика: большая, средняя, малая, примером нечеткого числа - значение: примерно 5, около 0.
Лингвистическим терм-множеством называется множество всех лингвистических значений, используемых для определения некоторой лингвистической переменной. Областью значений переменной является множество всех числовых значений, которые могут принимать определенный параметр изучаемой системы, или множество значений, существенное с точки зрения решаемой задачи.
Нечеткие множества:
Пусть
‒ универсальное множество, ‒
элемент, а
‒
элемент, а ‒
некоторое свойство. Обычное (четкое)
подмножество
‒
некоторое свойство. Обычное (четкое)
подмножество универсального множества
универсального множества , элементы которого удовлетворяют
свойству
, элементы которого удовлетворяют
свойству ,
определяются как множество упорядоченных
пар
,
определяются как множество упорядоченных
пар ,где
,где ‒ характеристическая функция, принимающая
значение 1, если удовлетворяет свойству, и 0 - в противном случае.
‒ характеристическая функция, принимающая
значение 1, если удовлетворяет свойству, и 0 - в противном случае.
Нечеткое
подмножество отличается от обычного
тем, что для элементов
 из
из нет однозначного ответа ”да-нет”
относительно свойства. В связи с этим,
нечеткое подмножество универсального
множества
нет однозначного ответа ”да-нет”
относительно свойства. В связи с этим,
нечеткое подмножество универсального
множества определяется как множество упорядоченных
пар
определяется как множество упорядоченных
пар ,
где
,
где ‒ характеристическая функция
принадлежности, принимающая значения
в некотором упорядоченном множестве
(например,
‒ характеристическая функция
принадлежности, принимающая значения
в некотором упорядоченном множестве
(например, ).
Функция принадлежности указывает
степень принадлежности элемента
).
Функция принадлежности указывает
степень принадлежности элемента множеству
множеству .
Множество
.
Множество называют множеством принадлежностей.
Если
называют множеством принадлежностей.
Если ,
то нечеткое множество может рассматриваться
как обычное четкое множество.
,
то нечеткое множество может рассматриваться
как обычное четкое множество.
Множество
элементов пространства  ,
для которых
,
для которых  ,
называется носителем нечеткого множества
,
называется носителем нечеткого множества
 и обозначается supp
A
:
и обозначается supp
A
:
Высота
нечеткого множества
 определяется как
определяется как
Нечеткое
множество
 называется нормальным тогда и только
тогда, когда
называется нормальным тогда и только
тогда, когда .
Если нечеткое множество
.
Если нечеткое множество не является нормальным, то его можно
нормализовать при помощи преобразования
не является нормальным, то его можно
нормализовать при помощи преобразования
 ,
,
где
 ‒ высота этого множества.
‒ высота этого множества.
Нечеткое
множество ,
является выпуклым тогда и только тогда,
когда для произвольных
,
является выпуклым тогда и только тогда,
когда для произвольных и
и выполняется
условие
выполняется
условие
2.1.1 Операции над нечеткими множествами
Включение.
Пусть
 и
и ‒ нечеткие множества на универсальном
множестве
‒ нечеткие множества на универсальном
множестве .
Говорят, что
.
Говорят, что содежится в
содежится в ,
если
,
если
Равенство. и равны, если
Дополнение.
Пусть
 ,
, и
и ‒ нечеткие множества, заданные на
‒ нечеткие множества, заданные на .
. и
и дополняют
друг друга, если.
дополняют
друг друга, если.
Пересечение.
 ‒
наибольшее нечеткое подмножество,
содержащееся одновременно в
‒
наибольшее нечеткое подмножество,
содержащееся одновременно в и
и :
:
Объединение.
 ‒ наибольшее нечеткое подмножество,
содержащее все элементы из
‒ наибольшее нечеткое подмножество,
содержащее все элементы из и
и :
:
Разность.
 ‒ подмножество с функцией принадлежности:
‒ подмножество с функцией принадлежности:
2.1.2 Нечеткие отношения
Пусть
 ‒
прямое произведение универсальных
множеств и
‒
прямое произведение универсальных
множеств и ‒
некоторое множество принадлежностей.
Нечеткое n-арное отношение определяется
как нечеткое подмножество
‒
некоторое множество принадлежностей.
Нечеткое n-арное отношение определяется
как нечеткое подмножество на
на , принимающее свои значения в
, принимающее свои значения в .
В случае
.
В случае и
и нечетким отношением
нечетким отношением между
множествами
между
множествами и
и будет
называться функция
будет
называться функция ,
которая ставит в соответствие каждой
паре элементов
,
которая ставит в соответствие каждой
паре элементов величину
величину .
.
Пусть

‒ нечеткое отношение
‒ нечеткое отношение между
между и
и , и
, и нечеткое отношение
нечеткое отношение между
между и
и .
Нечеткое отношение между
.
Нечеткое отношение между и
и ,
обозначаемое
,
обозначаемое ,
определенное через
,
определенное через и
и выражением,
называется композицией отношений
выражением,
называется композицией отношений и
и .
.
Нечеткая импликация.
Нечеткая
импликация представляет собой правило
вида: ЕСЛИ
 ТО
ТО ,где
,где – условие, а
– условие, а – заключение, причем
– заключение, причем и
и ‒ нечеткие множества, заданные своими
функциями принадлежности
‒ нечеткие множества, заданные своими
функциями принадлежности ,
, и областями определения
и областями определения ,
, соответственно. Обозначается импликация
как
соответственно. Обозначается импликация
как .
.
Различие между классической и нечеткой импликацией состоит в том, что в случае классической импликации условие и заключение могут быть либо абсолютно истинными, либо абсолютно ложными, в то время как для нечеткой импликации допускается их частичная истинность, со значением, принадлежащим интервалу . Такой подход имеет ряд преимуществ, поскольку на практике редко встречаются ситуации, когда условия правил удовлетворяются полностью, и по этой причине нельзя полагать, что заключение абсолютно истинно.
В нечеткой
логике существует множество различных
операторов импликации. Все они дают
различные результаты, степень эффективности
которых зависит в частности от моделируемой
системы. Одним из наиболее распространенных
операторов импликации является оператор
Мамдани, основанный на предположении,
что степень истинности заключения не может быть выше степени выполнения
условия
не может быть выше степени выполнения
условия :
:
2.2 Построение нечеткой системы
Из разработок искусственного интеллекта завоевали устойчивое признание экспертные системы, как системы поддержки принятия решений. Они способны аккумулировать знания, полученные человеком в различных областях деятельности. Посредством экспертных систем удается решить многие современные задачи, в том числе и задачи управления. Одним из основных методов представления знаний в экспертных системах являются продукционные правила, позволяющие приблизиться к стилю мышления человека. Обычно продукционное правило записывается в виде: «ЕСЛИ (посылка) (связка) (посылка)… (посылка) ТО (заключение)».Возможно наличие нескольких посылок в правиле, в этом случае они объединяются посредством логических связок «И», «ИЛИ».
Нечеткие системы (НС) тоже основаны на правилах продукционного типа, однако в качестве посылки и заключения в правиле используются лингвистические переменные, что позволяет избежать ограничений, присущих классическим продукционным правилам.
Таким образом, нечеткая система - это система, особенностью описания которой является:
нечеткая спецификация параметров;
нечеткое описание входных и выходных переменных системы;
нечеткое описание функционирования системы на основе продукционных «ЕСЛИ…ТО…»правил.
Важнейшим классом нечетких систем являются нечеткие системы управления (НСУ).Одним из важнейших компонентов НСУ является база знаний, которая представляет собой совокупность нечетких правил «ЕСЛИ–ТО», определяющих взаимосвязь между входами и выходами исследуемой системы. Существуют различные типы нечетких правил: лингвистическая, реляционная, модель Такаги-Сугено и др.
Для многих приложений, связанных с управлением процессами, необходимо построение модели рассматриваемого процесса. Знание модели позволяет подобрать соответствующий регулятор (модуль управления). Однако часто построение корректной модели представляет собой трудную проблему, требующую иногда введения различных упрощений. Применение теории нечетких множеств для управления процессами не предполагает знания моделей этих процессов. Следует только сформулировать правила поведения в форме нечетких условных суждений типа «ЕСЛИ-ТО».

Рисунок 2.1 -. Структура нечеткой системы управления
Процесс управления системой напрямую связан с выходной переменной нечеткой системы управления, но результат нечеткого логического вывода является нечетким, а физическое исполнительное устройство не способно воспринять такую команду. Необходимы специальные математические методы, позволяющие переходить от нечетких значений величин к вполне определенным. В целом весь процесс нечеткого управления можно разбить на несколько стадий: фаззификация, разработка нечетких правил и дефаззификация.
Фаззификаия подразумевает переход к нечеткости. На данной стадии точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно ‒ при помощи определенных функций принадлежности.
В нечеткой логике значения любой величины представляются не числами, а словами естественного языка и называются «термами». Так, значением лингвистической переменной «Дистанция» являются термы «Далеко», «Близко» и т. д. Для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Допустим переменная «Дистанция» может принимать любое значение из диапазона от 0 до 60 метров. Согласно положениям теории нечетких множеств, каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет степень принадлежностиданного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной «Дистанция». Тогда расстоянию в 50 метров можно задать степень принадлежности к терму «Далеко», равную 0,85, а к терму «Близко» ‒ 0,15. Задаваясь вопросом, сколько всего термов в переменной необходимо для достаточно точного представления физической величины принято считать, что достаточно 3-7 термов на каждую переменнуюдля большинства приложений. Большинствоприменений вполне исчерпывается использованием минимального количества термов.Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число 7 же обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
Принадлежность каждого точного значения к одному из термов лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным, однако сформировалось понятие о так называемых стандартных функциях принадлежности

Рисунок 2.2 ‒ Стандартные функции принадлежности
Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Следующей стадией является стадия разработки нечетких правил.
На ней определяются продукционные правила, связывающие лингвистические переменные. Большинство нечетких систем используют продукционные правила для описания зависимостей между лингвистическими переменными. Типичное продукционное правило состоит из антецедента (частьЕСЛИ …) и консеквента (часть ТО…). Антецедент может содержать более одной посылки. В этом случае они объединяются посредством логических связок«И» или «ИЛИ».
Процесс вычисления нечеткого правила называется нечетким логическим выводом и подразделяется на два этапа: обобщение и заключение.
Пусть имеется следующее правило:
ЕСЛИ «Дистанция» = средняя И «Угол» =малый, ТО «Мощность» = средняя.
На первом шаге логического вывода необходимо определить степень принадлежности всего антецедента правила. Для этого в нечеткой логике существуют два оператора: Min(…) и Max(…). Первый вычисляет минимальное значение степени принадлежности, а второй ‒ максимальное значение. Когда применять тот или иной оператор, зависит от того, какой связкой соединены посылки в правиле. Если использована связка «И», применяется оператор Min(…). Если же посылки объединены связкой «Или», необходимо применить оператор Max(…). Ну а если в правиле всего одна посылка, операторы вовсе не нужны.
Следующим шагом является собственно вывод или заключение. Подобным же образом посредством операторов Min/Maxвычисляется значение консеквента. Исходными данными служат вычисленные на предыдущем шаге значения степеней принадлежности антецедентов правил.
После выполнения всех шагов нечеткого вывода мы находим нечеткое значение управляющей переменной. Чтобы исполнительное устройство смогло отработать полученную команду, необходим этап управления, на котором мы избавляемся от нечеткости и который называется дефаззификацией.
На этапе дефаззификации осуществляется переход от нечетких значений величин к определенным физическим параметрам, которые могут служить командами исполнительному устройству.
Результат нечеткого вывода, конечно же, будет нечетким. Например, если речь идет об управлении механизмом и команда для электромотора будет представлена термом «Средняя» (мощность), то для исполнительного устройства это ровно ничего не значит. В теории нечетких множеств процедура дефаззификации аналогична нахождению характеристик положения (математического ожидания, моды, медианы) случайных величин в теории вероятности. Простейшим способом выполнения процедуры дефаззификации является выбор четкого числа, соответствующего максимуму функции принадлежности. Однако пригодность этого способа ограничивается лишь одно экстремальными функциями принадлежности. Для устранения нечеткости окончательного результата существует несколько методов: метод центра максимума, метод наибольшего значения, метод центроида и другие. Для многоэкстремальных функций принадлежности наиболее часто используется дефаззификация путем нахождения центра тяжести плоской фигуры, ограниченной осями координат и функцией принадлежности.
2.3. Модели нечеткого логического вывода
Нечеткий логический вывод - это аппроксимация зависимости «входы–выход» на основе лингвистических высказываний типа «ЕСЛИ–ТО» и операций над нечеткими множествами. Нечеткая модель содержит следующие блоки:
‒
фаззификатор, преобразующий фиксированный
вектор влияющих факторов Xв вектор
нечетких множеств
 ,
необходимых для выполнения нечеткого
логического вывода;
,
необходимых для выполнения нечеткого
логического вывода;
‒ нечеткая
база знаний, содержащая информацию о
зависимости
 в виде лингвистических правил типа
«ЕСЛИ–ТО»;
в виде лингвистических правил типа
«ЕСЛИ–ТО»;
‒ машина
нечеткого логического вывода, которая
на основе правил базы знаний определяет
значение выходной переменной в виде
нечеткого множества ,
соответствующего нечетким значениям
входных переменных
,
соответствующего нечетким значениям
входных переменных ;
;
‒
дефаззификатор, преобразующий выходное
нечеткое множество
 в четкое число Y.
в четкое число Y.

Рисунок 2.3 ‒ Структура нечеткой модели.
2.3.1Нечеткая модель типа Мамдани
Данный алгоритм описывает несколько последовательно выполняющихся этапов. При этом каждый последующий этап получает на вход значения полученные на предыдущем шаге.

Рисунок 2.4 – Диаграмма деятельности процесса нечеткого вывода
Алгоритм примечателен тем, что он работает по принципу «черного ящика». На вход поступают количественные значения, на выходе они же. На промежуточных этапах используется аппарат нечеткой логики и теория нечетких множеств. В этом и состоит элегантность использования нечетких систем. Можно манипулировать привычными числовыми данными, но при этом использовать гибкие возможности, которые предоставляют системы нечеткого вывода.
В модели типа Мамдани взаимосвязь между входами X = (x 1 , x 2 ,…, x n)и выходом y определяется нечеткой базой знаний следующего формата:
 ,
,
где
 -
лингвистический терм, которым оценивается
переменная x i в строке с номером
-
лингвистический терм, которым оценивается
переменная x i в строке с номером ;
; ),
где
),
где -
количество строк-конъюнкций, в которых
выход
-
количество строк-конъюнкций, в которых
выход оценивается
лингвистическим термом
оценивается
лингвистическим термом ;
; -
количество термов, используемых для
лингвистической оценки выходной
переменной
-
количество термов, используемых для
лингвистической оценки выходной
переменной .
.
С помощью операций ∪(ИЛИ) и ∩ (И) нечеткую базу знаний можно переписать в более компактном виде:
 (1)
(1)
Все лингвистические термы в базе знаний (1) представляются как нечеткие множества, заданные соответствующими функциями принадлежности.
Нечеткая база знаний (1) может трактоваться как некоторое разбиение пространства влияющих факторов на подобласти с размытыми границами, в каждой из которых функция отклика принимает значение, заданное соответствующим нечетким множеством. Правило в базе знаний представляет собой «информационный сгусток», отражающий одну из особенностей зависимости «входы–выход». Такие «сгустки насыщенной информации» или «гранулы знаний» могут рассматриваться как аналог вербального кодирования, которое, как установили психологи, происходит в человеческом мозге при обучении. Видимо поэтому формирование нечеткой базы знаний в конкретной предметной области, как правило, не составляет трудностей для эксперта.
Введем следующие обозначения:
 -
функция принадлежности входа
-
функция принадлежности входа нечеткому терму
нечеткому терму ,
, т.е
т.е
 -
функция принадлежности выхода y нечеткому
терму
-
функция принадлежности выхода y нечеткому
терму ,
т.е.
,
т.е.
Степень
принадлежности входного вектора
 нечетким термам
нечетким термам из базы знаний (1) определяется
следующей системой нечетких логических
уравнений:
из базы знаний (1) определяется
следующей системой нечетких логических
уравнений:
Наиболее часто используются следующие реализации: для операции ИЛИ - нахождение максимума, для операции И- нахождение минимума.
Нечеткое множество , соответствующее входному вектору X * , определяется следующим образом:

где imp- импликация, обычно реализуемая как операция нахождения минимума; agg- агрегирование нечетких множеств, которое наиболее часто реализуется операцией нахождения максимума.
Четкое
значение выхода
 ,
соответствующее входному вектору
,
соответствующее входному вектору ,
определяется в результате дефаззификации
нечеткого множества
,
определяется в результате дефаззификации
нечеткого множества .
Наиболее часто применяется дефаззификация
по методу центра тяжести:
.
Наиболее часто применяется дефаззификация
по методу центра тяжести:

Модели типа Мамдани и типа Сугэно будут идентичными, когда заключения правил заданы четкими числами, т. е. в случае, если:
1) термы d j выходной переменной в модели типа Мамдани задаются синглтонами - нечеткими аналогами четких чисел. В этом случае степени принадлежностей для всех элементов универсального множества равны нулю, за исключением одного со степенью принадлежности равной единице;
2) заключения правил в базе знаний модели типа Сугэно заданы функциями, в которых все коэффициенты при входных переменных равны нулю.
2.3.2 Нечеткая модель типа Сугэно
На сегодняшний день существует несколько моделей нечеткого управления, одной из которых является модель Такаги-Сугено.
Модель Такаги-Сугено иногда носит называние Takagi-Sugeno-Kang. Причина состоит в том, что этот тип нечеткой модели был первоначально предложен Takagi и Sugeno. Однако Канг и Сугено провели превосходную работу над идентификацией нечеткой модели. Отсюда и происхождение названия модели.
В
модели типа Сугэно взаимосвязь между
входами  и
выходом y задается
нечеткой базой знаний вида:
и
выходом y задается
нечеткой базой знаний вида:
где
 -
некоторые числа.
-
некоторые числа.
База
знаний (3) аналогична (1) за исключением
заключений правил  ,
которые задаются не нечеткими термами,
а линейной функцией от входов:
,
которые задаются не нечеткими термами,
а линейной функцией от входов:
 ,
,
Таким
образом, база знаний в модели типа Сугэно
является гибридной - ее правила содержат
посылки в виде нечетких множеств и
заключения в виде четкой линейной
функции. База знаний (3) может трактоваться
как некоторое разбиение пространства
влияющих факторов на нечеткие подобласти,
в каждой из которых значение функции
отклика рассчитывается как линейная
комбинация входов. Правила являются
своего рода переключателями с одного
линейного закона «входы–выход» на
другой, тоже линейный. Границы подобластей
размытые, следовательно, одновременно
могут выполняться несколько линейных
законов, но с различными весами.
Результирующее значение выхода
 определяется
как суперпозиция линейных зависимостей,
выполняемых в данной точке
определяется
как суперпозиция линейных зависимостей,
выполняемых в данной точке  n-мерного факторного
пространства. Это может быть
взвешенное среднее
n-мерного факторного
пространства. Это может быть
взвешенное среднее
 ,
,
или взвешенная сумма
 .
.
Значения
 рассчитываются
как и для модели типа Мамдани, т. е. по
формуле (2).Обратим внимание, что в модели
Сугэно в качестве операций ˄ и ˅обычно
используются соответственно вероятностное
ИЛИ и
умножение. В этом случае нечеткая модель
типа Сугэно может рассматриваться как
особый класс многослойных нейронных
сетей прямого распространения сигнала,
структура которой изоморфна базе знаний.
Такие сети получили название
нейро-нечетких.
рассчитываются
как и для модели типа Мамдани, т. е. по
формуле (2).Обратим внимание, что в модели
Сугэно в качестве операций ˄ и ˅обычно
используются соответственно вероятностное
ИЛИ и
умножение. В этом случае нечеткая модель
типа Сугэно может рассматриваться как
особый класс многослойных нейронных
сетей прямого распространения сигнала,
структура которой изоморфна базе знаний.
Такие сети получили название
нейро-нечетких.
Нечеткая логика (НЛ) подразумевает проведение операции нечеткого логического вывода, основой которого является база правил, а также функция принадлежности лингвистических терм. Результатом является четкое значение переменной.
Нечетким логическим выводом называется аппроксимация зависимости с помощью нечеткой базы знаний и операций над нечеткими множествами.
Для того что бы выполнить нечеткий логический вывод необходимы следующие условия:
Должно существовать как минимум одно правило для каждого лингвистического терма выходной переменной;
Для любого терма входной переменной должно быть хотя бы одно правило, в которой этот терм используется в качестве предпосылки;
Между правилами не должно быть противоречий и корреляции.
На рисунке 1.7. изображена последовательность действий при использовании процесса нечеткого логического вывода.

Рисунок 1.7 – Последовательность действий при использовании
процесса нечеткого логического вывода
Нечеткий логический вывод занимает центральное место в нечеткой логике и системах нечеткого управления. Этот процесс представляет собой процедуру или алгоритм получения нечетких заключений на основе нечетких условий или предпосылок.
Системы нечеткого логического вывода являются частным случаем продукционных нечетких систем, в которых условия и заключения, отдельных правил формулируются в форме нечетких высказываний относительно значений тех или иных лингвистических переменных.
Разработка и применение систем нечеткого логического вывода включают в себя несколько этапов, реализация которых выполняется с помощью рассмотренных ранее основных положений нечетких множеств.
Входные переменные, поступающие на вход системы нечеткого логического вывода, являются информацией, которая замеряется каким-либо образом. Эти переменные есть реальные переменные процесса управления. Управляющие переменные системы управления формируются на выходе системы нечеткого логического вывода.
Таким образом, системы нечеткого логического вывода предназначены для преобразования значений входных переменных процесса управления в выходные переменные на основе использования нечетких правил продукций. Простейший вариант правила нечеткой продукции, который наиболее часто используется в системах нечеткого логического вывода, записывается в форме:
ПРАВИЛО<#>: ЕСЛИ “β 1 есть α 1 ”,ТО “β 2 есть α 2 ”
Здесь нечеткое высказывание “β 1 есть α 1 ” представляет собой условие данного правила нечеткой продукции, а нечеткое высказывание “β 2 есть α 2 ” – нечеткое заключение данного правила, которые сформулированы в терминах нечетких лингвистических высказываний. При этом считается, что β 1 ≠ β 2 .
Основные этапы нечеткого логического вывода и особенности каждого из них более подробно рассмотрены ниже:
1) Формирование базы правил. База правил систем нечеткого логического вывода предназначена для формального представления эмпирических знаний или знаний экспертов в той или иной проблемной области и представляет собой совокупность правил нечетких продукций вида: ПРАВИЛО_1: ЕСЛИ “Условие _1”,ТО “Заключение_1”(F 1)
ПРАВИЛО_2: ЕСЛИ “Условие _2”,ТО “Заключение_2”(F 2)
ПРАВИЛО_n: ЕСЛИ “Условие _n”,ТО “Заключение_n”(F n)
Здесь F i (i принадлежит {1, 2, …, n} ) есть коэффициенты определенности или весовые коэффициенты соответствующих правил, которые могут принимать значения из интервала . Если не указано иначе, то F i =1 .
Таким образом, база правил считается заданной, если для нее определено множество правил нечетких продукций, множество входных лингвистических переменных и множество выходных лингвистических переменных.
2) Фаззификация (введение нечеткости) является процессом и процедурой нахождения значений функций принадлежности нечетких множеств (термов) на основе обычных (четких) исходных данных. После завершения этого этапа для всех входных переменных должны быть определены конкретные значения функций принадлежности по каждому из лингвистических термов, которые используются в подусловиях базы правил системы нечеткого логического вывода.
3) Агрегирование представляет собой процедуру определения степени истинности условий по каждому из правил системы нечеткого логического вывода. Если условие правила имеет простую форму, то степень его истинности равна соответствующему значению принадлежности входной переменной к терму, используемому в данном условии. В том случае, когда условие состоит из нескольких подусловий вида:
ПРАВИЛО<#>: ЕСЛИ “β 1 есть α 1 ” И “β 2 есть α 2 ”,ТО “β 3 есть ν”, или
ПРАВИЛО<#>: ЕСЛИ “β 1 есть α 1 ” ИЛИ “β 2 есть α 2 ”,ТО “β 3 есть ν”,
то определяется степень истинности сложного высказывания на основе известных значений истинности подусловий. При этом используются соответствующие формулы для выполнения нечеткой конъюнкции и нечеткой дизъюнкции:
§ Нечеткая логическая конъюнкция (И)
§ Нечеткая логическая дизъюнкция (ИЛИ)
4) Активизация есть процесс нахождения степени истинности каждого из подзаключений правил нечетких продукций. До начала этого этапа предполагаются известными степень истинности и весовой коэффициент (F i ) для каждого правила. Далее рассматривается каждое из заключений правил системы нечеткого логического вывода. Если заключение правила представляет собой одно нечеткое высказывание, то степень его истинности равна алгебраическому произведению соответствующей степени истинности условия на весовой коэффициент.
Когда заключение состоит из нескольких подзаключений вида:
ПРАВИЛО<#>: ЕСЛИ “β 1 есть α 1 ” ТО “β 2 есть α 2 ” И “β 3 есть ν”, или
ПРАВИЛО<#>: ЕСЛИ “β 1 есть α 1 ” ТО “β 2 есть α 2 ” ИЛИ “β 3 есть ν”,
то степень истинности каждого из подзаключений равна алгебраическому произведению соответствующего значения степени истинности условия на весовой коэффициент.
После нахождения множества С i ={c 1 , c 2 , … , c n } степеней истинности каждого из подзаключений определяются функции принадлежности каждого из них для рассматриваемых выходных лингвистических переменных. Для этого используется один из следующих методов:
· Min-активизация: μ’(y)=min{C i , μ(y)};
· Prod- активизация: μ’(y)=C i *μ(y);
· Average- активизация:μ’(y)=0.5*(C i +μ(y)),
где μ’(y) – функция принадлежности терма, который является значением некоторой выходной переменной y j , заданной на универсуме Y .
5) Аккумуляция является процессом нахождения функции принадлежности для каждой из выходных лингвистических переменных. Цель аккумуляции – объединить все степени истинности заключений (подзаключений) для получения функции принадлежности каждой из выходных переменных. Причина необходимости этого этапа заключается в том, что подзаключения, относящиеся к одной и той же выходной лингвистической переменной, принадлежат различным правилам системы нечеткого логического вывода. Объединение нечетких множеств C i производят с помощью формулы:
,
где – модальное значение (мода) нечеткого множества, соответствующего выходной переменной после аккумуляции, рассчитываемое по формуле:
6) Дефаззификация (приведение к четкости) представляет собой процедуру нахождения обычного (четкого) значения для каждой из выходных лингвистических переменных. Цель заключается в том, чтобы, используя результаты аккумуляции всех выходных лингвистических переменных, получить обычное количественное значение каждой из выходных переменных, которое может быть использовано специальными устройствами, внешними по отношению к системе нечеткого логического вывода. Для выполнения численных расчетов на завершающем данном этапе могут быть использованы следующие методы дефаззификации (рисунок 1.8):

Centroid - центр тяжести; Bisector - медиана; SOM (Smallest Of Maximums) - наименьший из максимумов;
LOM (Largest Of Maximums) - наибольший из максимумов; MOM (Mean Of Maximums) - центр максимумов.
Рисунок 1.8 – Основные методы дефаззификации
1. Метод центра тяжести (Centre of Gravity) считается одним из самых простых по вычислительной сложности, но достаточно точным методом. Расчет производится по формуле:

где - это результат дефаззификации (точное значение выходной переменной); – границы интервала носителя нечеткого множества выходной переменной; - функция принадлежности нечеткого множества, соответствующего выходной переменной после этапа аккумуляции.
Для дискретного варианта:

где – число элементов в области для вычисления «центра тяжести».
2. Метод центра площади (Centre of Area):

где - это результат дефаззификации (точное значение выходной переменной); Min и Max - левая и правая точка носителя нечеткого множества выходной переменной; - функция принадлежности нечеткого множества, соответствующего выходной переменной после этапа аккумуляции.
Нечеткие множества. Лингвистическая переменная. Нечеткая логика. Нечеткий вывод. Композиционное правило вывода.
(Конспект)
В основе понятия нечеткого множества (НИ) лежит представление о том, что обладающие общим свойством элементы некоторого множества могут иметь различные степени вырожденности этого свойства и, следовательно, различную степень принадлежности этому свойству.
Пусть U некоторое множество. Нечетким множеством Ã в U называется совокупность пар вида {(µ Ã (u), u)}, где u U, µ Ã .
Значение µ Ã называется степенью принадлежности объекта к нечеткому множеству U.
µ Ã : U
µ Ã – называется функцией принадлежности.
Пример нечетких множеств – возраст людей (рис. 19.1).

По аналогии с традиционной теорией множеств в Теории НМ определяются следующие операции:
Объединение:
![]() ,
где
,
где
![]()
Перечисление:
![]() ,
,
Дополнение:
Алгебраическое произведение:
![]() ,
где
,
где
n-арным нечетким отношением
определенным на множествах называется
нечеткое подмножество декартовых
произведений
![]()
Так как нечеткое отношение является множеством для него справедливы все операции определенные для нечетких множеств. В практических приложениях теории нечетких множеств важную роль играет операция композиции нечетких отношений.
Композиция нечетких отношений
Пусть заданы 2 двухместных нечетких отношения:
Композиция нечетких отношений определяется следующим выражением:
 Степени
принадлежности конкретных выражений
Степени
принадлежности конкретных выражений



Лингвистическая переменная - - это пятерка Х – имя переменной (возраст), U – базовое множество (0…150), Т(х) – терм множества. Множества лингвистических значений(молодой, средних лет, пожилой, старый). Каждое лингвистическое значение является меткой нечеткого множества определенного на U. G – синтаксическое правило, порождающее лингвистическое значение переменной Х (очень молодой, очень старый). М – семантическое правило ставящее в соответствие каждому лингвистическому значению нечеткое подмножество базового множества, то есть функция принадлежности.
Нечетким высказыванием называется утверждение относительно которого в данный момент времени можно судить о степени его истинности или ложности. Истинность принимает значение в интервале . Нечеткое высказывание не допускающее разделения на более простые называется элементарным.
Нечеткое высказывание построенное на элементарных с использованием логических связок называется составным нечетким высказыванием. Логическим связкам соответствуют операции над истинностью нечетких высказываний. - степени истинности конкретных высказываний.
2)
![]()
Таким образом алгебра нечетких множеств изоморфна алгебре нечетких высказываний.
4) операция импликации
Для операции импликации в нечеткой логике предложено несколько определений. Основные:
1)
![]()
2)
![]()
3)
![]()
5) Эквивалентность
n-местным нечетким предикатом, определенным на множествах U 1 , U 2 ,…,U n называется выражение содержащее предметные переменные данных множеств и превращающиеся в нечеткие высказывания при замене предметных переменных элементами множеств U 1 , U 2 ,…,U n .
Пусть U 1 , U 2 ,…,U n базовые множества лингвистических переменных, а в качестве символов предметных переменных выступают иена лингвистических переменных. Тогда примерами нечетких предикатов являются:
«давление в цилиндре низкое» - одноместный предикат
«температура в котле значительно выше температуры в теплообменнике» - двуместных предикат.

Если U k =1,5 следовательно «давление в котле низкое» = 0,7
При построении и реализации нечетких алгоритмов важную роль играет композиционное правило вывода.
Пусть - нечеткое отображение
Нечеткое подмножество универсума U, тогда порождает в V нечеткое подмножество

![]()
композиционное правило вывода является основой при построении логического вывода в нечеткой логике.
Пусть задано нечеткое высказывание , где и – нечеткие множества. Пусть также того задано некоторое высказывание (близкое к А, но не тождественное ему).
В классической логике широко используется правило вывода Modus Ponens
Это правило обобщается на случай нечеткой логики следующим образом:
Пусть множество и определены на базовом множестве Х, а и на базовом множестве Y. Естественно считать, что высказывание если задает некоторое нечеткое отображение из множества Х в Y
![]()
Тогда в соответствии с композиционным правилом вывода имеем:
Отношение строится на основе определения операции импликации в нечеткой логики.
1)

Если температура в котле низкая (), то подогрев повышенный ()


Реальные нечеткие логические алгоритмы содержат не одно, а множество продукционных правил
Если S 1 , то R 1 , иначе
Если S n , то R n , иначе
Поэтому нечеткие отношения должны быть построены для каждого отдельного правила, а затем агрегированы путем наложения друг на друга



В качестве агрегирующей операции выбирается или min или max в зависимости от типа импликации. композиционного вывода (правило свертки). В рассматриваемой логической системе предпосылки определяются лингвистическими переменными А1,А2,А3, а заключение – лингвистической переменной ...
Методология нечеткого управления автономной фотоветроэнергетической системой
Реферат >> ИнформатикаОдну нечеткую или лингвистическую переменную , нечеткую функцию или нечеткое отношение. Тогда нечеткий ... нечеткой импликацией. Фактически нечеткий вывод на рис. 2 является применением максминной композиции в качестве композиционного правила нечеткого вывода ...
... основе агентно-ориентированного подхода и диалоговых логик
Диссертация >> Информатика, программирование... вывода на диалоговом произведении многозначных и нечетких логик ... лингвистические ... логики малой размерности, однако, с увеличением мощности множества истинностных значений конструирование и использование правил вывода ... значений переменных , образованных...
Система "Aлор-Трейд"
Дипломная работа >> Финансовые наукиЗначок - это правило композиционного вывода (правило свертки) /3/. В рассматриваемой логической системе предпосылки определяются лингвистическими переменными , а заключение - лингвистической переменной В. В каждом...
Шпаргалки по управленческим решениям
Шпаргалка >> МенеджментОт множества субъективных факторов – логика ... являются значениями лингвистической переменной X. Допустим, что множество решений характеризуется... определяется на основе композиционного правила вывода : G = Аº D, где G - нечеткое подмножество интервала I. ...